1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
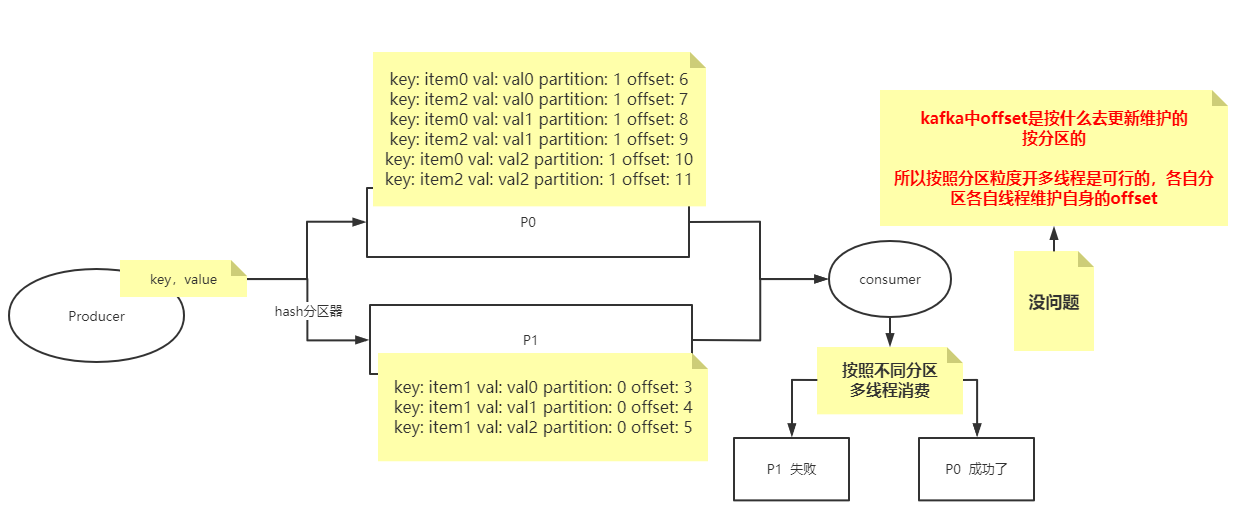
@Test
public void producer() throws ExecutionException, InterruptedException {
String topic = "msb-items";
Properties p = new Properties();
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092,node02:9092,node03:9092");
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p);
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future<RecordMetadata> send = producer
.send(record);
RecordMetadata rm = send.get();
int partition = rm.partition();
long offset = rm.offset();
System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
|