Kafka的索引机制
索引存储机制
Kafka的索引存储机制是什么?
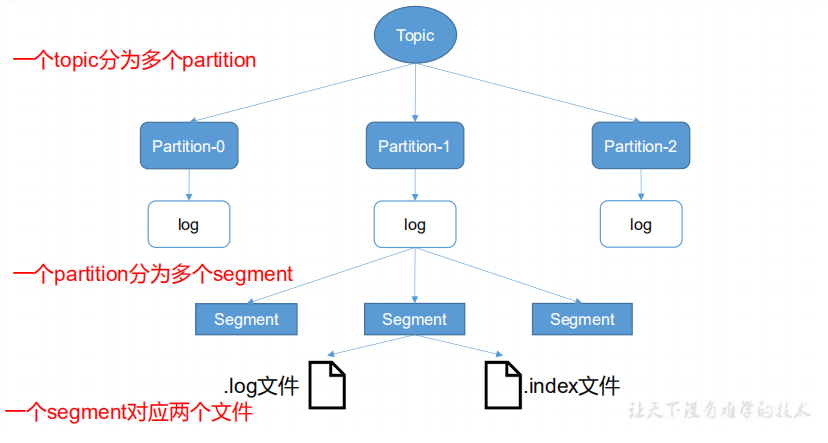
一个Topic分为多个Partition,一个Partition分为多个Segment。
每个Segment对应三个文件:偏移量索引文件、时间戳索引文件、消息存储文件
为什么要采用这种分片和索引的机制?
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,采用分片的机制,由于顺序遍历效率慢,采用了索引机制。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。
1 | 00000000000000000000.index |
Kafka 中的索引文件以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项,也就是说Offset是不连续的,是一个区间范围。
以偏移量索引文件来做具体分析。偏移量索引项的格式如下图所示。
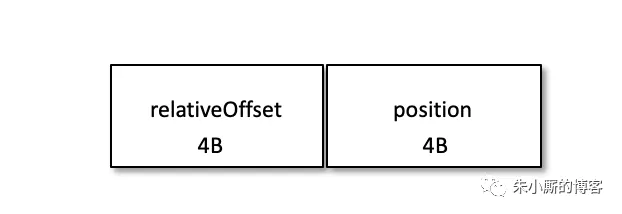
每个索引项占用 8 个字节,分为两个部分:
(1) relativeOffset: 相对偏移量,表示消息相对于 baseOffset 的偏移量,占用 4 个字节,当前索引文件的文件名即为 baseOffset 的值。
(2) position: 物理地址,也就是消息在日志分段文件中对应的物理位置,占用 4 个字节。
为什么要使用相对偏移量
relativeOffset,而不使用绝对偏移量offset呢?
消息的偏移量(offset)占用 8 个字节,也可以称为绝对偏移量。
索引项中没有直接使用绝对偏移量而改为只占用 4 个字节的相对偏移量(relativeOffset = offset - baseOffset),这样可以减小索引文件占用的空间。
索引搜索机制
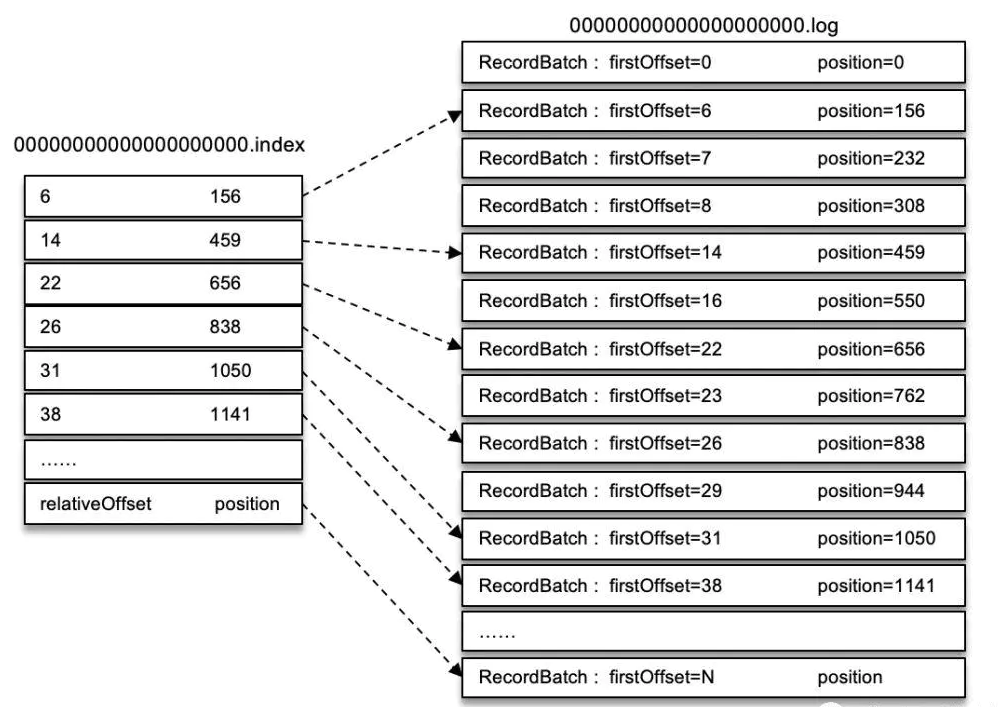
如果我们要查找偏移量为 23 的消息,首先通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即[22, 656],然后从日志分段文件中的物理位置 656 开始顺序查找偏移量为 23 的消息。
为什么不采用连续的Offset,而要采用区间范围的形式?
为了降低内存空间的占用,连续的Offset会占用更多的内存空间。
索引文件中的区间是根据什么来决定的?
每当写入一定量 (由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB) 的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。
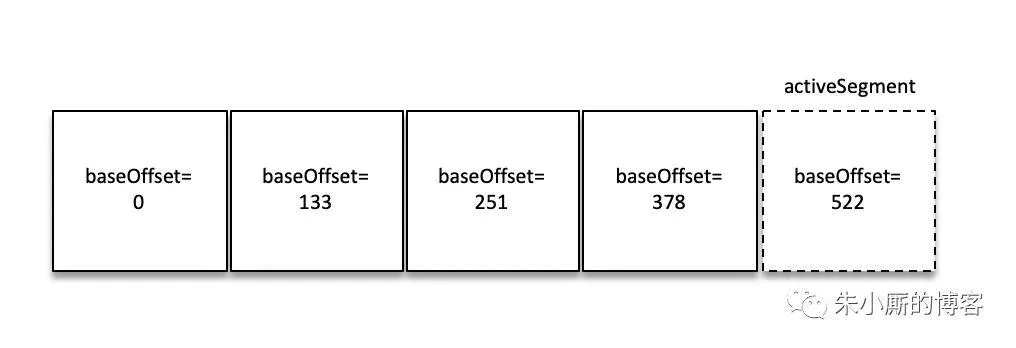
如果要查找偏移量为 268 的消息,那么应该怎么办呢?
首先肯定是定位到baseOffset为251的日志分段,然后计算相对偏移量relativeOffset = 268 - 251 = 17,之后再在对应的索引文件中找到不大于 17 的索引项,最后根据索引项中的 position 定位到具体的日志分段文件位置开始查找目标消息。
那么又是如何查找 baseOffset 为 251 的日志分段的呢?
这里并不是顺序查找,而是用了跳跃表ConcurrentSkipListMap 的结构。
Kafka 的每个日志对象中使用了 ConcurrentSkipListMap 来保存各个日志分段,每个日志分段的 baseOffset 作为 key,这样可以根据指定偏移量来快速定位到消息所在的日志分段。
在Kafka中要定位一条消息,那么首先根据 offset 从 ConcurrentSkipListMap 中来查找到到对应(baseOffset)日志分段的索引文件,然后读取偏移量索引索引文件,之后使用二分法在偏移量索引文件中找到不大于 offset - baseOffset z的最大索引项,接着再读取日志分段文件并且从日志分段文件中顺序查找relativeOffset对应的消息。
Kafka中通过offset查询消息内容的整个流程我们可以简化成下图:

Kafka和MySQL的索引区别
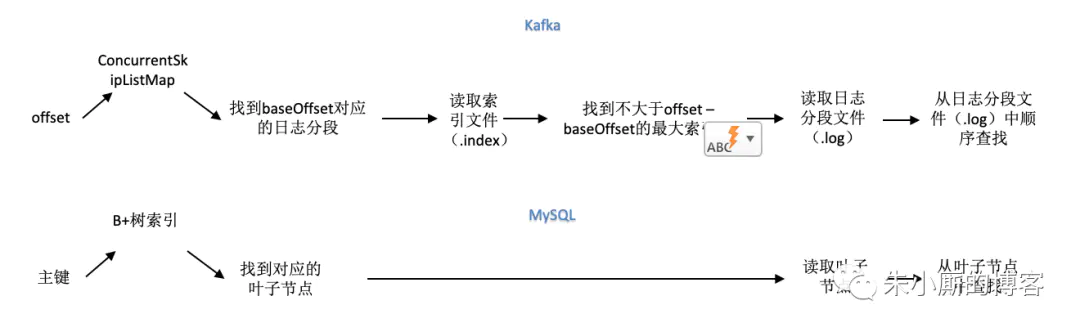
InnoDB中维护索引的代价比Kafka中的要高。Kafka中当有新的索引文件建立的时候ConcurrentSkipListMap才会更新,而不是每次有数据写入时就会更新,这块的维护量基本可以忽略,B+树中数据有插入、更新、删除的时候都需要更新索引,还会引来“页分裂”等相对耗时的操作。Kafka中的索引文件也是顺序追加文件的操作,和B+树比起来工作量要小很多。
MySQL中需要频繁地执行CRUD的操作,CRUD是MySQL的主要工作内容,而为了支撑这个操作需要使用维护量大很多的B+树去支撑。
Kafka中的消息一般都是顺序写入磁盘,再到从磁盘顺序读出(不深入探讨page cache等),他的主要工作内容就是:写入+读取,很少有检索查询的操作
换句话说,检索查询只是Kafka的一个辅助功能,不需要为了这个功能而去花费特别太的代价去维护一个高level的索引。
Kafka中的这种方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中。
相关参考:kafka的索引机制
最后更新: 2021年03月08日 13:49
