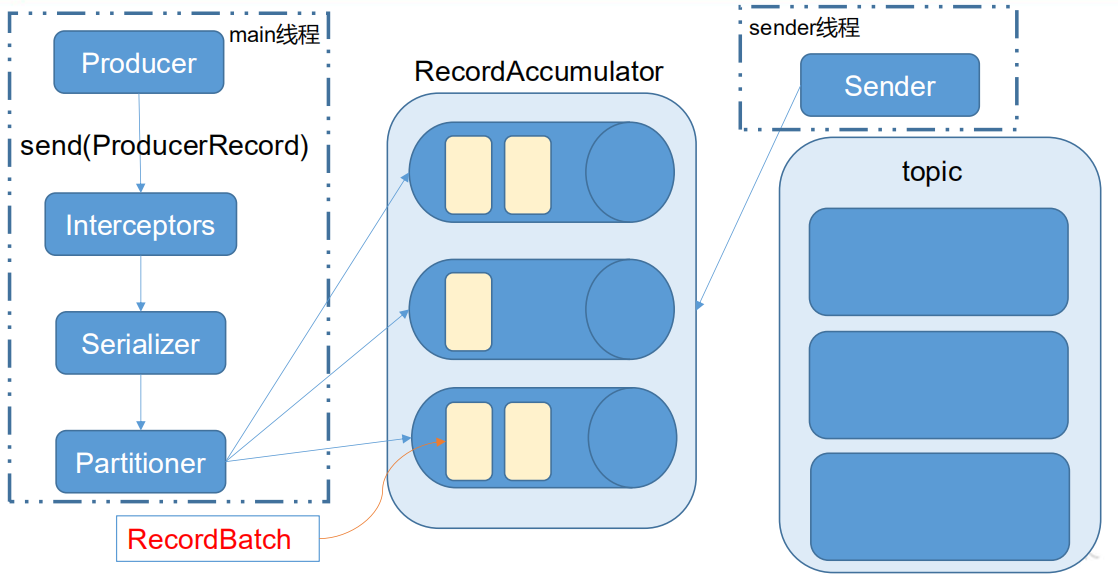
Kafka API Producer API Kafka 的 Producer 发送消息采用的是异步发送 的方式。在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程 ,以及一个线程共享变量——RecordAccumulator(相当于缓冲区) 。RecordAccumulator 中拉取消息发送到 Kafka broker。
batch.size :只有数据积累到 batch.size 之后,sender 才会发送数据。linger.ms :如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。
1 2 3 4 5 <dependency > <groupId > org.apache.kafka</groupId > <artifactId > kafka-clients</artifactId > <version > 0.11.0.0</version > </dependency >
1 2 3 KafkaProducer:需要创建一个生产者对象,用来发送数据 ProducerConfig:获取所需的一系列配置参数 ProducerRecord:每条数据都要封装成一个 ProducerRecord 对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import org.apache.kafka.clients.producer.*;import java.util.Properties;public class CustomProducer public static void main (String[] args) throws Exception Properties props = new Properties(); props.put("bootstrap.servers" , "192.168.163.129:9092" ); props.put("acks" , "all" ); props.put("retries" , 1 ); props.put("batch.size" , 16384 ); props.put("linger.ms" , 1 ); props.put("buffer.memory" , 33554432 ); props.put("key.serializer" , "org.apache.kafka.common.serialization.StringSerializer" ); props.put("value.serializer" , "org.apache.kafka.common.serialization.StringSerializer" ); Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0 ; i < 10 ; i++) { producer.send(new ProducerRecord<String, String>("first" , Integer.toString(i), Integer.toString(i))); } producer.close(); } }
Properties中的Key的值可以参考ProducerConfig配置类,里面提供了很多静态常量。
1 2 3 public Future<RecordMetadata> send (ProducerRecord<K, V> record, Callback callback)
自定义分区器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public interface Partitioner extends Configurable , Closeable public int partition (String topic, Object key, byte [] keyBytes, Object value, byte [] valueBytes, Cluster cluster) public void close () }
1 2 props.put("partitioner.class" ,"cn.midkuro.MyPartitioner" );
Consumer API Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
1 2 3 4 5 6 7 8 KafkaConsumer:需要创建一个消费者对象,用来消费数据 ConsumerConfig:获取所需的一系列配置参数 ConsuemrRecord:每条数据都要封装成一个 ConsumerRecord 对象 为了使我们能够专注于自己的业务逻辑,Kafka 提供了自动提交 offset 的功能。 自动提交 offset 的相关参数: enable.auto.commit:是否开启自动提交 offset 功能 auto.commit.interval.ms:自动提交 offset 的时间间隔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Arrays;import java.util.Properties;public class CustomConsumer public static void main (String[] args) Properties props = new Properties(); props.put("bootstrap.servers" , "192.168.163.129:9092" ); props.put("group.id" , "test" ); props.put("enable.auto.commit" , "true" ); props.put("auto.commit.interval.ms" , "1000" ); props.put("auto.offset.reset" ,"earliest" ); props.put("key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" ); props.put("value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" ); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("first" )); while (true ) { ConsumerRecords<String, String> records = consumer.poll(100 ); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s%n" , record.offset(), record.key(), record.value()); } } }
如何让消费者重新消费某一个topic的数据?
换消费者组,并且auto.offset.reset = earliest
不管offset存储在zk中,或者是kafka本地中,消费者启动时,只会去拉取一次offset的值,然后将该值存储到内存中,消费者自己内存维护offset的更新。
假设消费者启动时向服务器拉取了offset = 10,消费了10条信息后,offset = 20,假设这时候消费者宕机了,重启后,将会拉取到offset = 10,因为消费者处理了数据但没有commit offset,服务器的offset没有更新。
提交策略 1 2 3 自动提交: enable.auto.commit:是否开启自动提交 offset 功能 auto.commit.interval.ms:自动提交 offset 的时间间隔
自动提交 offset 十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset 提交的时机。因此 Kafka 还提供了手动提交 offset 的 API :
1 2 3 4 commitSync(同步提交): 阻塞当前线程,一直到提交成功,并且会自动失败重试 commitAsync(异步提交): 没有失败重试机制,故有可能提交失败 两种方式都会将本次 poll 的一批数据最高的偏移量提交
1 2 3 4 5 6 7 8 9 10 11 12 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); while (true ) { ConsumerRecords<String, String> records = consumer.poll(100 ); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n" , record.offset(), record.key(), record.value()); } consumer.commitSync(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete (Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) if (exception != null ) { System.err.println("Commit failed for" + offsets); } } });
无论是自动提交、同步提交还是异步提交 offset,都有可能会造成数据的漏消费或者重复消费。先
提交 offset 后消费,有可能造成数据的漏消费;而先消费后提交 offset,有可能会造成数据
的重复消费。
自定义存储 offsetKafka 0.9 版本之前,offset 存储在 zookeeper,0.9 版本及之后,默认将 offset 存储在 Kafka的一个内置的 topic 中。除此之外,Kafka 还可以选择自定义存储 offset。
offset 的维护是相当繁琐的,因为需要考虑到消费者的 Rebalace。
当有新的消费者加入消费者组、已有的消费者推出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做 Rebalance。
消费者发生 Rebalance 之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的 offset 位置继续消费。
要实现自定义存储 offset,需要借助 ConsumerRebalanceListener ,以下为示例代码,其中提交和获取 offset 的方法,需要根据所选的 offset 存储系统自行实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private static Map<TopicPartition, Long> currentOffset = new HashMap<>();ConsumerRebalanceListener rebalance = new ConsumerRebalanceListener() { @Override public void onPartitionsRevoked (Collection<TopicPartition> partitions) commitOffset(currentOffset); } @Override public void onPartitionsAssigned (Collection<TopicPartition> partitions) currentOffset.clear(); for (TopicPartition partition : partitions) { consumer.seek(partition, getOffset(partition)); } } }; consumer.subscribe(Arrays.asList("first" ), rebalance); while (true ) { ConsumerRecords<String, String> records = consumer.poll(100 ); for (ConsumerRecord<String, String> record : records) { System.out.println("消费消息..." ); currentOffset.put(new TopicPartition(record.topic(), record.partition()), record.offset()); } commitOffset(currentOffset); } private static long getOffset (TopicPartition partition) return 0 ; } private static void commitOffset (Map<TopicPartition, Long> currentOffset) }
这种自定义存储offset的好处在于可以将offset放在数据库中,从而保证消费消息的事务和offset的事务是同一个,避免了数据丢失。
自定义Interceptor 拦截器原理 Producer 拦截器(interceptor)是在 Kafka 0.10 版本被引入的,主要用于实现 clients 端的定制化控制逻辑。
对于 producer 而言,interceptor 使得用户在消息发送前以及 producer 回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。
同时,producer 允许用户指定多个 interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor 的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public interface ProducerInterceptor <K , V > extends Configurable public ProducerRecord<K, V> onSend (ProducerRecord<K, V> record) public void onAcknowledgement (RecordMetadata metadata, Exception exception) public void close () }
1 2 3 4 public interface Configurable void configure (Map<String, ?> configs) }
拦截器案例 实现一个简单的双 interceptor 组成的拦截链。
第一个 interceptor 会在消息发送前将时间戳信息加到消息 value 的最前部。
第二个 interceptor 会在消息发送后更新成功发送消息数或失败发送消息数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class TimeInterceptor implements ProducerInterceptor <String , String > @Override public void configure (Map<String, ?> configs) } @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(), System.currentTimeMillis() + "," + record.value().toString()); } @Override public void onAcknowledgement (RecordMetadata metadata, Exception exception) } @Override public void close () } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class CounterInterceptor implements ProducerInterceptor <String , String > private int errorCounter = 0 ; private int successCounter = 0 ; @Override public void configure (Map<String, ?> configs) } @Override public ProducerRecord<String, String> onSend (ProducerRecord<String, String> record) return record; } @Override public void onAcknowledgement (RecordMetadata metadata, Exception exception) if (exception == null ) { successCounter++; } else { errorCounter++; } } @Override public void close () System.out.println("Successful sent: " + successCounter); System.out.println("Failed sent: " + errorCounter); } }
这两个拦截器也可以合并成一个,分开是为了解耦。
1 2 3 4 5 6 7 8 9 10 Properties props = new Properties(); List<String> interceptors = new ArrayList<>(); interceptors.add("com.midkuro.interceptor.TimeInterceptor" ); interceptors.add("com.midkuro.interceptor.CounterInterceptor" ); props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);