Kafka 基本概念
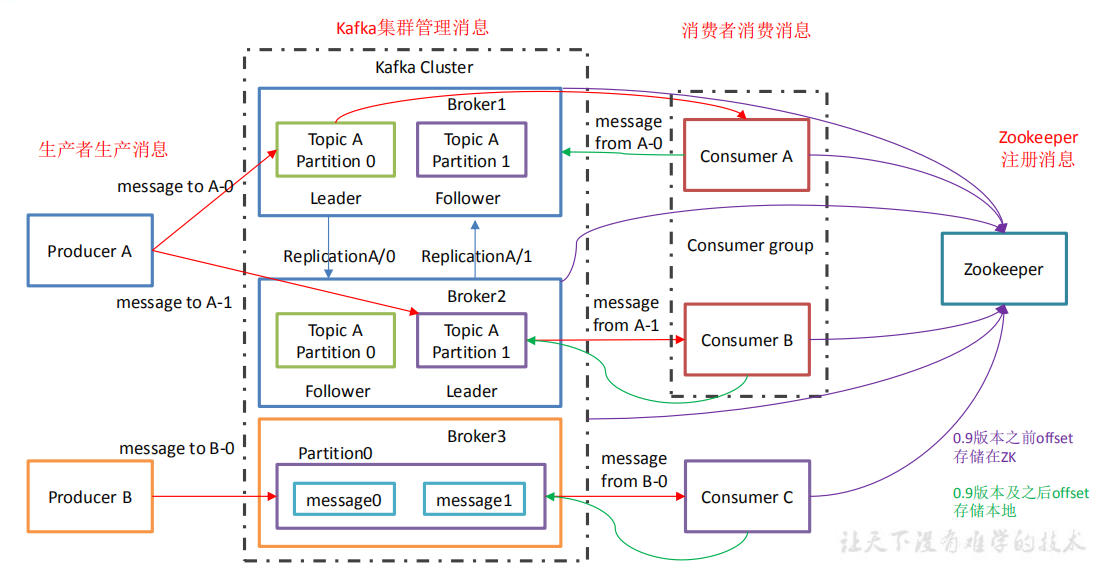
在0.9之前的版本中,offset存放在ZK中,在0.9之后的版本中,存放在kafka cluster中,原因是因为消费者本身就需要和kafka集群打交道,而没必要频繁地和ZK进行通信。
在ZK中,会产生一个Controller的节点,存储kafka集训相关的信息,最先启动的kafka机器充当集群的老大,主要和zookeeper做协调和交互。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Producer :消息生产者,就是向 kafka broker 发消息的客户端; Consumer :消息消费者,向 kafka broker 取消息的客户端; Consumer Group :消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费; 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。 Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。 Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列; Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失且 kafka 仍然能够继续工作 kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本一个 leader 和若干个 follower。 leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。 follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。 leader 发生故障时,某个 follower 会成为新的 follower。
kafka的消费原理和RocketMQ相似,和消费者所属的组相关,如果所有的消费者都属于一个消费者组,那么一个消费者能消费到该消息,如果均属于不同的组,所有消费者均能消费到该消息。
安装 官网地址
配置 1 2 3 4 5 6 7 8 9 10 11 12 13 [root@localhost software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/ [root@localhost module]$ mv kafka_2.11-0.11.0.0/ kafka [root@localhost kafka]$ mkdir logs [root@localhost kafka]$ cd config/ [root@localhost config]$ vi server.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 broker.id =0 delete.topic.enable =true num.network.threads =3 num.io.threads =8 socket.send.buffer.bytes =102400 socket.receive.buffer.bytes =102400 socket.request.max.bytes =104857600 log.dirs =/opt/module/kafka/data num.partitions =1 num.recovery.threads.per.data.dir =1 log.retention.hours =168 zookeeper.connect =192.168.163.128:2181,192.168.163.129:2181,192.168.163.130:2181
1 2 3 4 5 6 7 8 9 10 [root@localhost module]$ sudo vi /etc/profile export KAFKA_HOME=/opt/module/kafkaexport PATH=$PATH :$KAFKA_HOME /bin[root@localhost module]$ source /etc/profile
启动和关闭 谁先启动,谁就是集群中的Master
1 2 3 4 5 6 [root@localhost kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [root@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [root@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
1 2 3 4 [root@localhost kafka]$ bin/kafka-server-stop.sh stop [root@hadoop103 kafka]$ bin/kafka-server-stop.sh stop [root@hadoop104 kafka]$ bin/kafka-server-stop.sh stop
命令操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@localhost kafka]$ bin/kafka-topics.sh --zookeeper 192.168.163.129:2181 --create --replication-factor 3 --partitions 1 --topic first [root@localhost kafka]$ bin/kafka-topics.sh --zookeeper 192.168.163.129:2181 --list [root@localhost kafka]$ bin/kafka-topics.sh --zookeeper 192.168.163.129:2181 --describe --topic first [root@localhost kafka]$ bin/kafka-topics.sh --zookeeper 192.168.163.129:2181 --alter --topic first --partitions 6 [root@localhost kafka]$ bin/kafka-topics.sh --zookeeper 192.168.163.129:2181 --delete --topic first [root@localhost kafka]$ bin/kafka-console-producer.sh --broker-list 192.168.163.129:9092 --topic first >hello world >atguigu atguigu [root@localhost kafka]$ bin/kafka-console-consumer.sh --zookeeper 192.168.163.129:2181 --topic first [root@localhost kafka]$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.163.129:9092 --topic first [root@localhost kafka]$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.163.129:9092 --from-beginning --topic first
kafka默认采用轮训的方式决定消息发送到哪个分区,主题持久化在磁盘中,offset也存储在kafka集群本地磁盘中 。
可以通过查看之前配置的data目录验证:
1 2 3 4 5 6 drwxr-xr-x. 2 root root 141 2月 27 00:13 first-0 drwxr-xr-x. 2 root root 141 2月 27 00:16 __consumer_offsets-6 drwxr-xr-x. 2 root root 141 2月 27 00:16 __consumer_offsets-9
0.9前的kafka版本中,topic的各个partition的各个group消费情况:【offsets】放在了zookeeper中,新版把这个offsert保存到了一个__consumer_offsert的topic下 ,默认是有50个分区,通过轮训的编号打散在各个broker中。
SHELL免密登录 通过129机器生成ssh密钥,下发公钥到130和131机器上,进行免密登录配置。
1 2 3 4 5 6 7 8 9 [root@localhost ~]$ cd ~/.ssh/ [root@localhost ~]$ ssh-keygen -t rsa [root@localhost ~]$ ssh-copy-id 192.168.163.130
批量拷贝 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@localhost ~]$ yum -y install rsync 命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称 rsync -rvl $pdir /$fname $user @host:$pdir /$fname -r 递归 -v 显示复制过程 -l 拷贝符号连接 [root@localhost opt]$ rsync -rvl /opt/module/kafka/ root@192.168.1.130:/opt/module/kafka/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@localhost bin]$ vi xsync.sh #!/bin/bash pcount=$# if ((pcount==0)); then echo no args;exit ;fi p1=$1 fname=`basename $p1 ` echo fname=$fname pdir=`cd -P $(dirname $p1 ); pwd ` echo pdir=$pdir user=`whoami` for i in 192.168.163.130 192.168.163.131do echo "========== $i ==========" rsync -rvl $pdir /$fname $user @$i :$pdir done [root@localhost bin]$ chmod 777 xsync.sh [root@localhost bin]$ sh xsync.sh /opt/module/kafka/
群起脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@localhost ~]$ vi kk.sh #!bin/bash case $1 in "start" ){ for i in 192.168.163.129 192.168.163.130 192.168.163.131 do echo "========== $i ==========" ssh $i '/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties' done };; "stop" ){ for i in 192.168.163.129 192.168.163.130 192.168.163.131 do echo "========== $i ==========" ssh $i '/opt/module/kafka/bin/kafka-server-stop.sh' done };; esac