HashMap的源码和分析
JDK1.8
HashMap
AVL树:
在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
特点:
1.本身首先是一棵二叉搜索树。
2.带有平衡条件:每个结点的左右子树的高度之差的绝对值(平衡因子)最多为1。
也就是说,AVL树,本质上是带了平衡功能的二叉查找树(二叉排序树,二叉搜索树)。
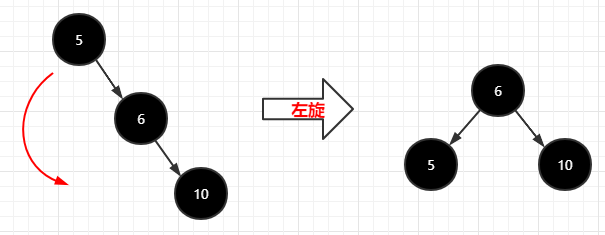
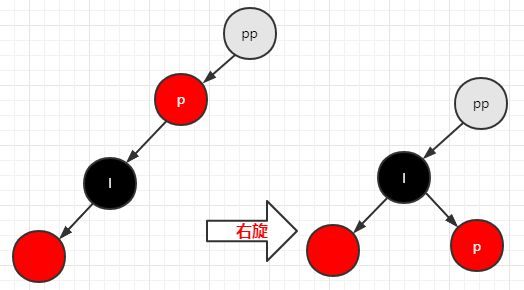
树的左旋:绕着子结点逆时针转动,如下图:
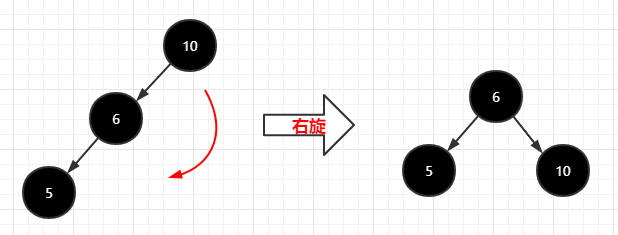
树的右旋:绕着子结点顺时针转动,如下图
红黑树:
是一种自平衡二叉查找树,是一种特化的AVL树,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
若一棵二叉查找树是红黑树,则它的任一子树必为红黑树。红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但 对之进行平衡的代价较低, 其平均统计性能要强于 AVL 。
红黑树的实际应用非常广泛,比如Linux内核中的完全公平调度器、高精度计时器、ext3文件系统等等,各种语言的函数库如Java的TreeMap和TreeSet。
红黑树的定义如下:
1.每个结点是红的或者黑的
2.根结点是黑的
3.每个叶结点是黑的(每个结点有默认的黑色的NULL结点)
4.如果一个结点是红的,则它的两个儿子都是黑的(父子结点之间不能出现两个连续的红结点)
5.对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点(黑色平衡)
在算法导论中,新插入的结点优先默认是红色的,优先满足第五条定义,再满足其他定义。
案例
1.假设现在插入一个根结点(10)
1 | 步骤: |
2.再插入一个结点(20)
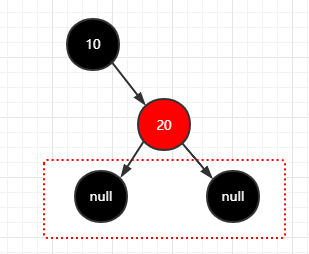
1 | 步骤: |
这是一颗正常的红黑树。因为每个节点,它的末尾节点都有隐藏的黑色空节点,所以满足第三条定义。
再插入一个结点(30)
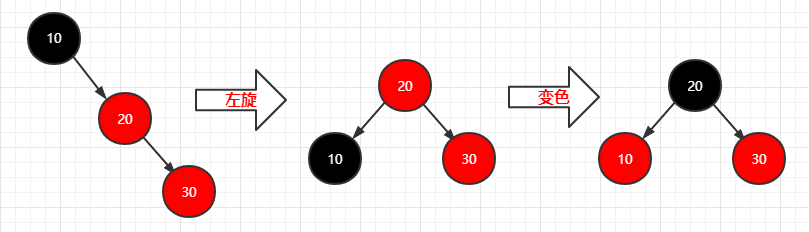
1 | 步骤: |
再插入一个结点(40)
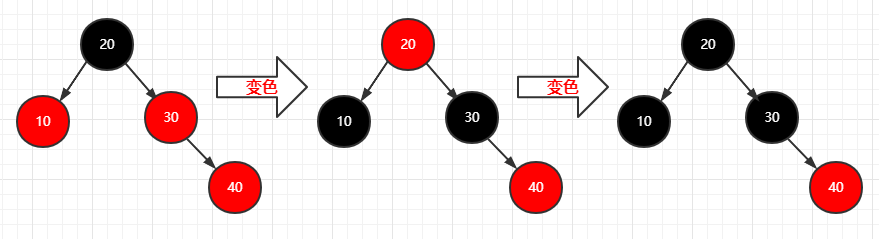
1 | 步骤: |
再插入两个结点(5)(25)
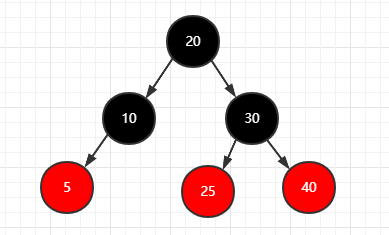
1 | 步骤: |
再插入一个结点(50)
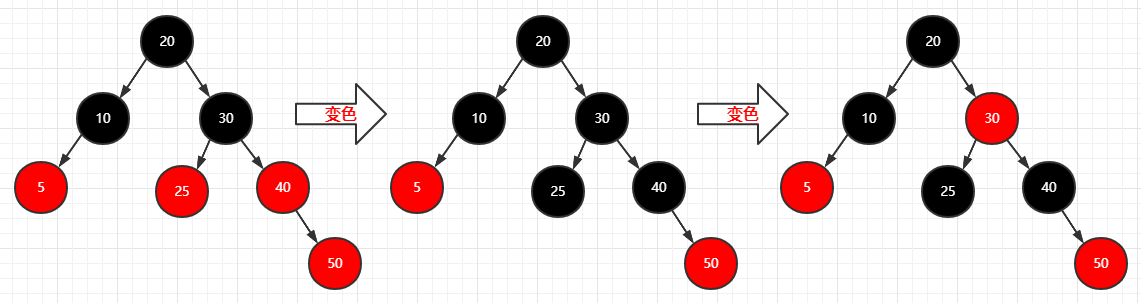
1 | 步骤: |
再插入两个结点(35)(60)
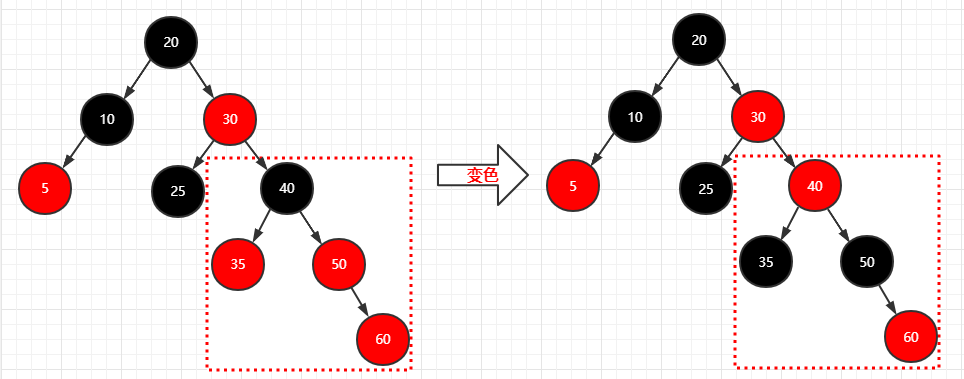
1 | 步骤: |
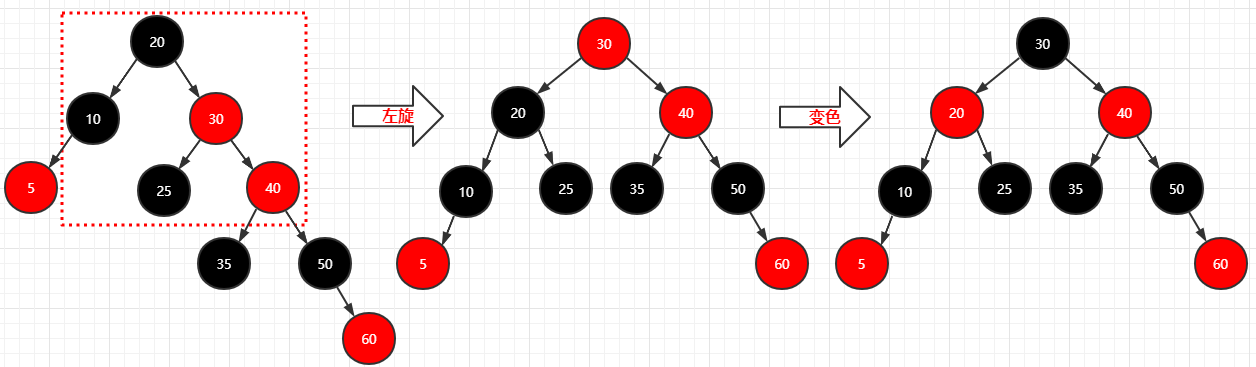
1 | 步骤: |
再插入个结点(6)
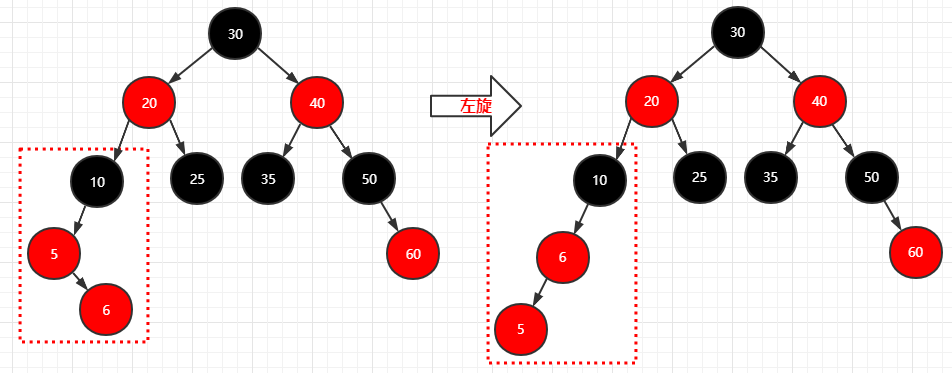
1 | 步骤: |
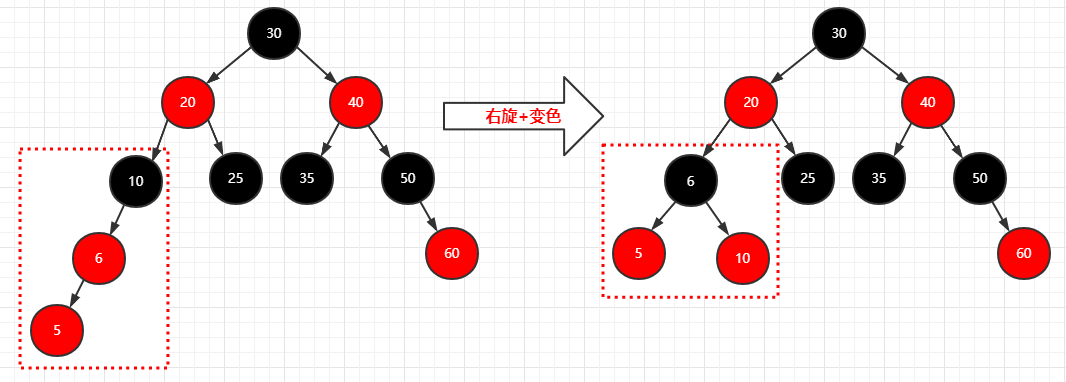
1 | 步骤: |
总结
当插入一个新节点(红色)时:
父节点是黑色的,不用进行调整
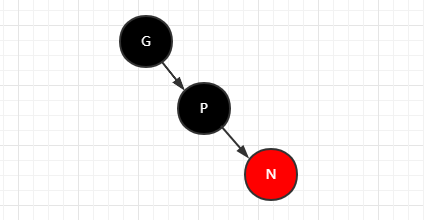
父节点是红色的,并且
1.叔叔是空的,旋转+变色
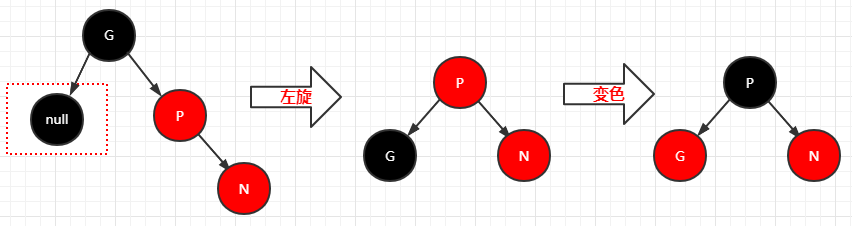
2.叔叔是红色,父节点+叔叔节点变黑色,祖父节点变红色
3.叔叔是黑色,旋转+变色
源码
1 | //当链表长度达到阈值8时,转换成红黑树 |
1 | //红黑树存储结构对象 |
所以说,上文TreeNode实际上是Node的子类,它有着两个属性,一个next,一个prev,也就是说,TreeNode还是一个双向链表。
1 | public V put(K key, V value) { |
1 | static final int hash(Object key) { |
由于JDK1.8的HashMap有了红黑树的保障,所以相对于计算Hash值没有JDK1.7那么复杂。
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
在JDK1.7中,采用头插法插入到链表的头部,而在JDK1.8中,采用的是尾插法插入到链表中,并且当链表的数量大于8时,也就是添加第九个元素时,会调用树化方法treeifyBin,根据条件将链表转换成红黑树。
1 | //链表树化红黑树 |
1 | //把Node类型转换成TreeNode类型 |
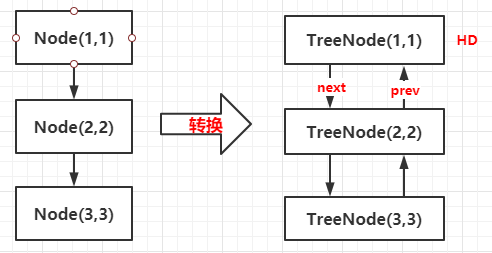
接下来是真正的将链表树化的逻辑方法:
1 | final void treeify(Node<K,V>[] tab) { |
1 | static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) { |
上文的方法主要是分析当插入新节点时,链表结构转换成红黑树的行为,如果插入新节点时,红黑树已经存在,则将调用putTreeVal方法:
1 | final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, |
1 | /* |
1 | //左旋 |
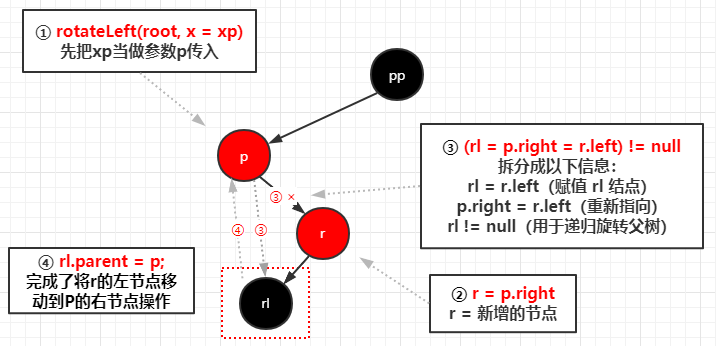
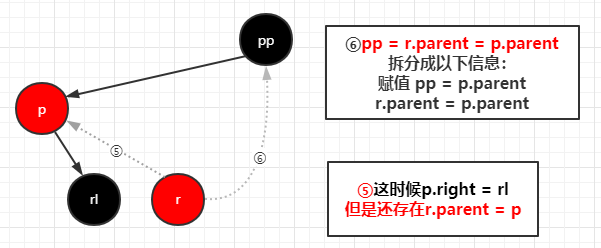
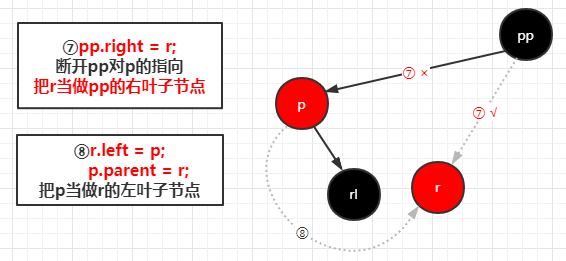
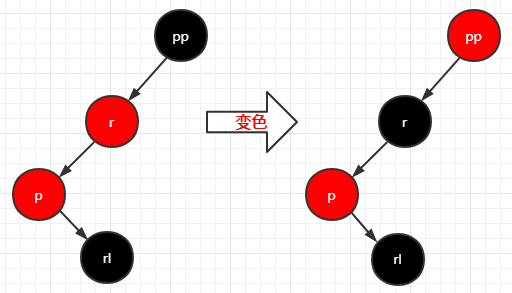
完成左旋之后进行变色,变完色之后右旋
1 | //通过调用 root = rotateLeft(root, xpp); 所以参数 p = xpp |
再看一下扩容方法:
1 | final Node<K,V>[] resize() { |
红黑树的扩容:
1 | final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) { |
1 | //遍历双向链表,把TreeNode类型转换成Node类型,建立单向链表,返回头结点 |
HashMap的get方法:
1 | public V get(Object key) { |
1 | final Node<K,V> getNode(int hash, Object key) { |
1 | final TreeNode<K,V> getTreeNode(int h, Object k) { |
1 | /* |
ConcurrentHashMap
1 | //表示当前的整个ConcurrentHashMap正在扩容 |
1 | //把整个红黑树结构封在TreeBin对象中 |
ConcurrentHashMap的数组中将存储Node类型和TreeBin类型,TreeBin用于承载红黑树的整个结构,其中有一个root属性存储红黑树的根节点。
这样做的目的是为了后面对红黑树根节点加锁时,直接对TreeBin对象加锁,可以不用考虑在加锁的过程中,红黑树的根节点变化情况。
1 | public V put(K key, V value) { |
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
1 | private final Node<K,V>[] initTable() { |
1 | private final void treeifyBin(Node<K,V>[] tab, int index) { |
1 | //用于累加计数元素数量 |
1 | //x 表示需要增加的值 |
1 | //x:累加值 wasUncontended: false 表示已经进行过CAS操作并且失败了 |
1 | //用该对象占用在数组上,表示这个位置正在扩容 |
1 | //在putval中,有一个分值逻辑代码是这样的,表示如果当前的f.hash == MOVED时,则进行帮助扩容逻辑 |
1 | //多线程进行扩容操作 |
1 | //tab 原数组 , nextTab 新数组 |
分析完添加元素和累加计数的分治方法之后,再看看统计元素大小的size方法:
1 | public int size() { |
1 | //baseCount + CounterCell[] 的数据,累加起来就是总的Size |
HashMap区别
JDK7和JDK8中的HashMap底层数据结构有什么区别?
1 | JDK7:数组 + 链表 |
JDK8中的HashMap为什么要使用红黑树?
1 | 当元素个数小于一个阈值时,链表在整体效率上要高于红黑树,当元素个数大于此阈值时,链表整体的查询效率要低于红黑树,此阈值在HashMap中为8。转换成红黑树可以平衡插入和查询效率。 |
JDK8中的HashMap什么时候将链表转化成红黑树?
1 | 当链表中的元素大于8,并且数组的长度大于等于64时,才会将链表转化成红黑树。 |
JDK8中的HashMap的put方法的实现过程?
1 | 1.根据Key生成HashCode |
JDK8中HashMap的get方法的实现过程
1 | 1.根据Key生成HashCode |
JDK7与JDK8中HashMap的不同点
1 | 1.JDK8使用了红黑树 |
ConcurrentHashMap区别
JDK7中的ConcurrentHashMap是怎么保证并发安全的?
1 | 利用 Unsafe操作 + ReentrantLock + 分段思想 |
JDK7中的ConcurrentHashMap的底层原理
1 | ConcurrentHashMap底层是由两层嵌套数组实现的: |
JDK8中的ConcurrentHashMap是怎么保证并发安全的?
1 | 利用 Unsafe操作 + synchronized关键字 |
JDK8中的ConcurrentHashMap的put方法的实现流程?
1 | 当向ConcurrentHashMap中put一个Key,Value时: |
JDK7和JDK8中,统计元素个数的实现逻辑有什么区别?
1 | JDK7: |
JDK7和JDK8中,都支持多线程并发扩容吗?
1 | 都支持多线程扩容。 |
“本篇文章主要摘自参考资料”
最后更新: 2021年02月04日 19:15
