/** * The default initial capacity - MUST be a power of two. */ //HashMap初始化容量大小,默认是16 staticfinalint DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
1 2 3 4 5 6 7
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ //HashMap最大的容量大小 staticfinalint MAXIMUM_CAPACITY = 1 << 30;
1 2 3 4 5
/** * The load factor used when none specified in constructor. */ //HashMap的扩容因子,默认是0.75 staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f;
1 2 3 4 5 6 7 8 9 10
/** * The next size value at which to resize (capacity * load factor). * @serial */ // If table == EMPTY_TABLE then this is the initial capacity at which the // table will be created when inflated. //阈值,当table == {}时,该值为初始容量(初始容量默认为16); //当table被填充了,也就是为table分配内存空间后,threshold一般为 capacity*loadFactory。 //HashMap在进行扩容时需要参考threshold int threshold;
1 2 3 4 5
/** * The number of key-value mappings contained in this map. */ //当前HashMap存储的键值对数量 transientint size;
1 2 3 4 5 6 7 8 9
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ //用于计算链表中的修改次数 transientint modCount;
1 2 3 4 5
/** * An empty table instance to share when the table is not inflated. */ //HashMap内部的存储结构是一个数组,此处数组为空,即没有初始化之前的状态 staticfinal Entry<?,?>[] EMPTY_TABLE = {};
1 2 3 4 5
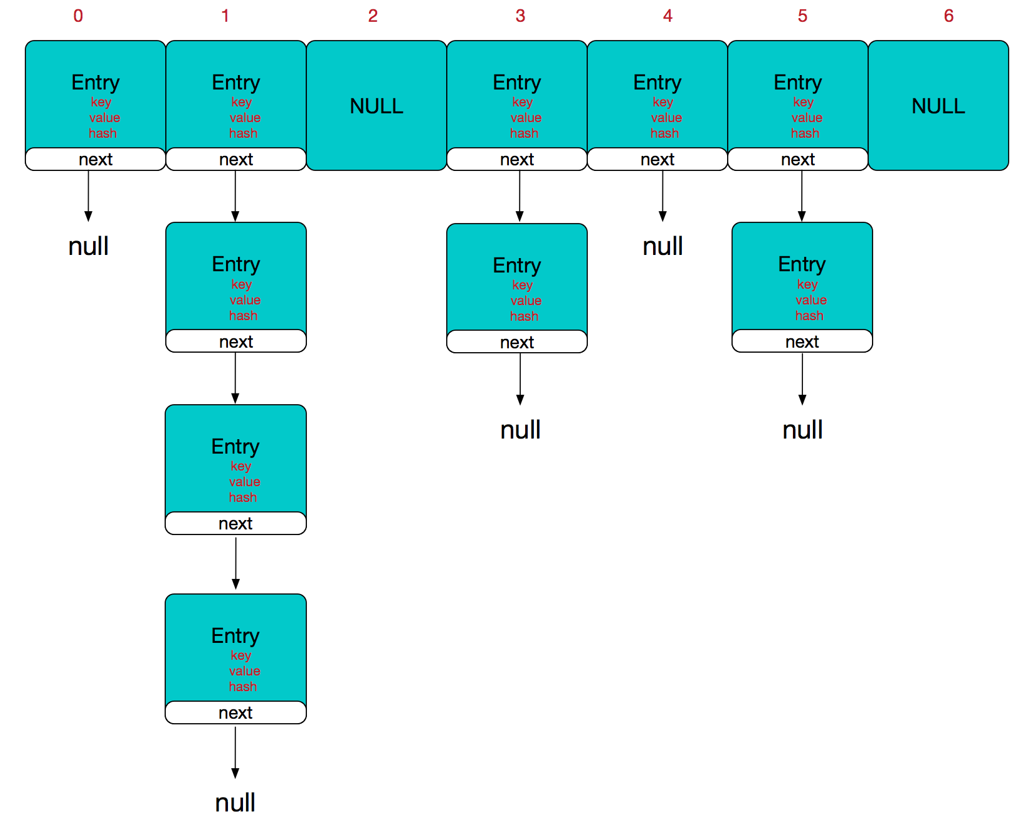
/** * The table, resized as necessary. Length MUST Always be a power of two. */ //HashMap的主干数组,就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
staticclassEntry<K,V> implementsMap.Entry<K,V> { final K key; V value; Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构 int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } }
/** * Returns index for hash code h. */ staticintindexFor(int h, int length){ // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
finalinthash(Object k){ int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } //当hashSeed!=0时,计算时hash值将加入哈希种子打散hash值的分布 h ^= k.hashCode();
// This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
/** * int hash: 当前Key的Hash值 * bucketIndex: 数组下标 */ voidaddEntry(int hash, K key, V value, int bucketIndex){ //判断是否需要扩容 if ((size >= threshold) && (null != table[bucketIndex])) { //需要扩容时,传参传入了table.length的长度的两倍 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
createEntry(hash, key, value, bucketIndex); }
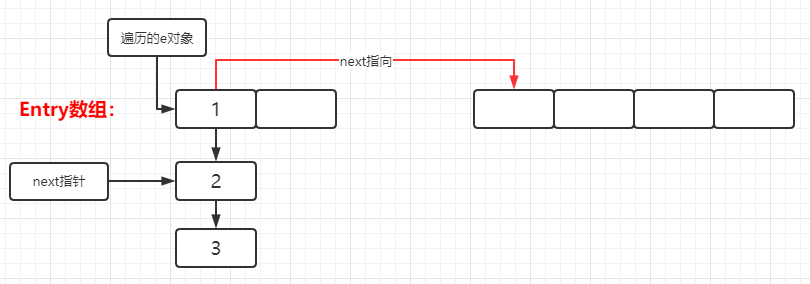
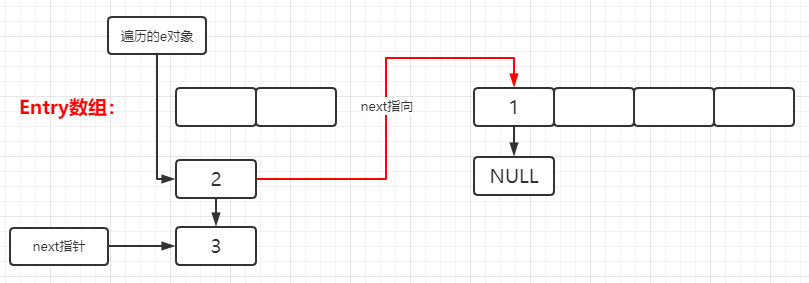
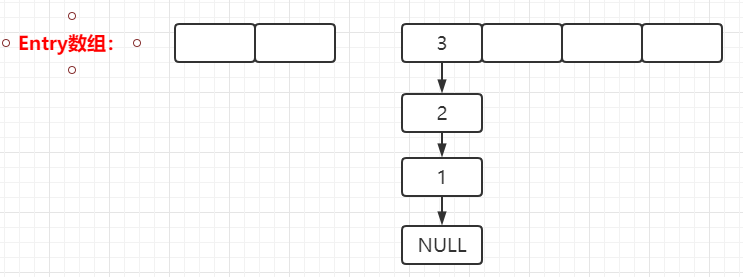
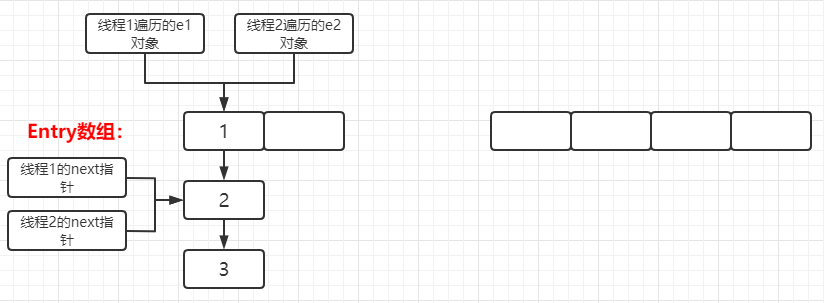
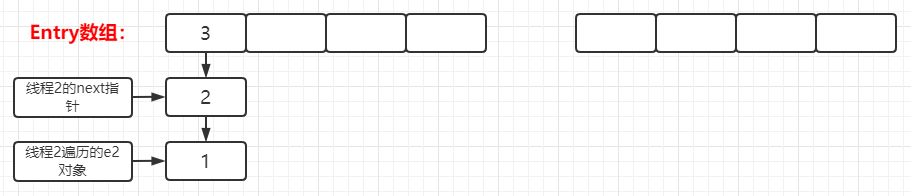
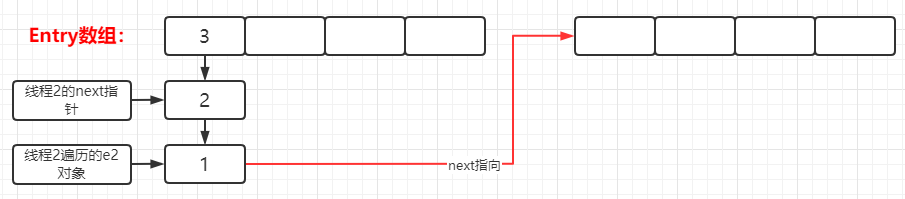
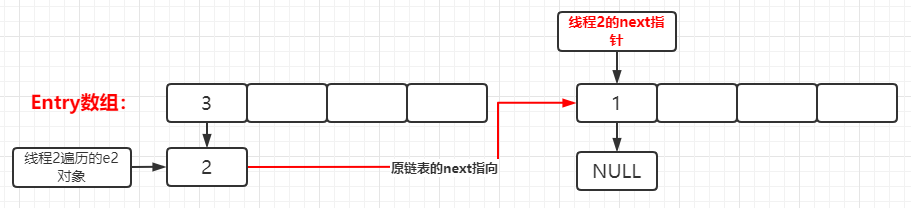
voidcreateEntry(int hash, K key, V value, int bucketIndex){ //获取当前链表的表头 Entry<K,V> e = table[bucketIndex]; //将key-value键值对赋予到新Entry对象中,并通过头插入法,其Entry的next属性指向原链表表头 //则新的Entry对象成为了链表的新表头,并将该表头存储在table数组中。 table[bucketIndex] = new Entry<>(hash, key, value, e); //添加新元素,hashMap的元素数量++ size++; }
在HashMap的属性中,定义了一个transient int modCount;,用来记录该对象的修改次数,是hashMap提供的一种快速失败机制(fast fail),用于迭代遍历时校验对象是否被修改,当集合在迭代过程中对象被其他线程并发修改时,将会抛出ConcurrentModificationException异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
final Entry<K,V> nextEntry(){ //在遍历集合之前会将modCount赋值给expectedModCount,接着遍历过程中会不断验证modCount是否发生变化 if (modCount != expectedModCount) thrownew ConcurrentModificationException(); Entry<K,V> e = next; if (e == null) thrownew NoSuchElementException();
if ((next = e.next) == null) { Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } current = e; return e; }
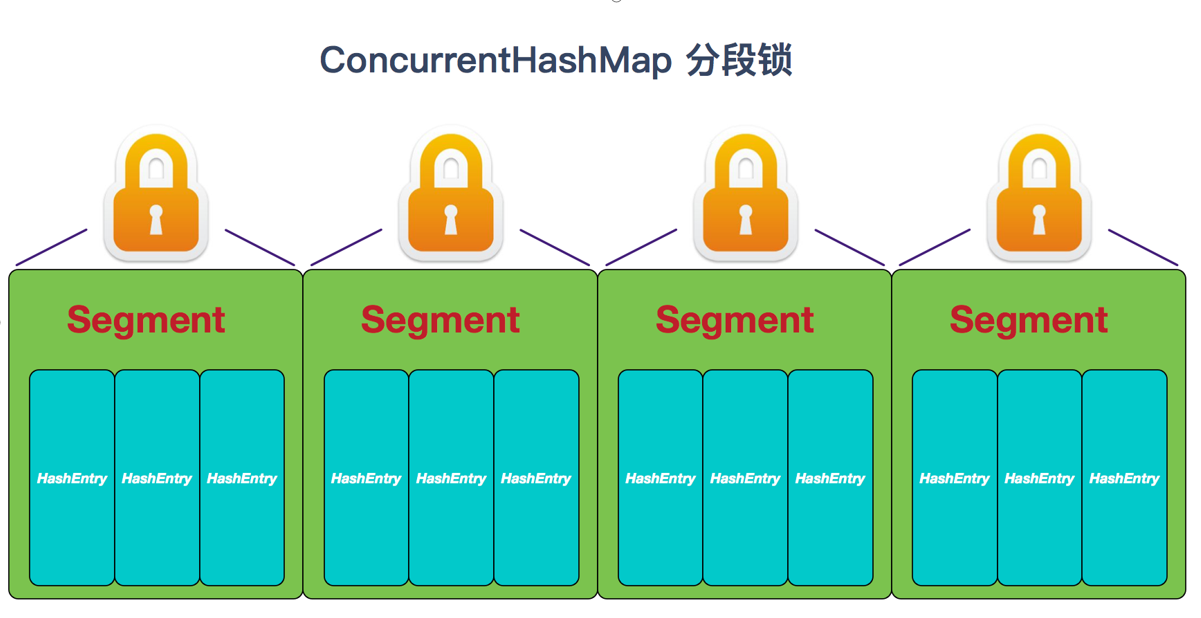
/** * The default concurrency level for this table, used when not * otherwise specified in a constructor. */ //并发级别,用于计算一个Segment负责管理多少个Entry数组 staticfinalint DEFAULT_CONCURRENCY_LEVEL = 16;
1 2 3 4 5 6 7
/** * The minimum capacity for per-segment tables. Must be a power * of two, at least two to avoid immediate resizing on next use * after lazy construction. */ //规定了segment中的HashEntry数组最小容量,数组容量必须是2的次方数 staticfinalint MIN_SEGMENT_TABLE_CAPACITY = 2;
1 2 3 4 5 6 7 8 9 10
/** * The maximum number of times to tryLock in a prescan before * possibly blocking on acquire in preparation for a locked * segment operation. On multiprocessors, using a bounded * number of retries maintains cache acquired while locating * nodes. */ //获取锁失败时,tryLock循环的最大次数,获取当前CPU核数,大于1则设置成64 staticfinalint MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
1 2 3 4 5 6
/** * The maximum number of segments to allow; used to bound * constructor arguments. Must be power of two less than 1 << 24. */ //规定了segment数组的最大值不能超过2的16次方 staticfinalint MAX_SEGMENTS = 1 << 16; // slightly conservative
1 2 3 4 5 6
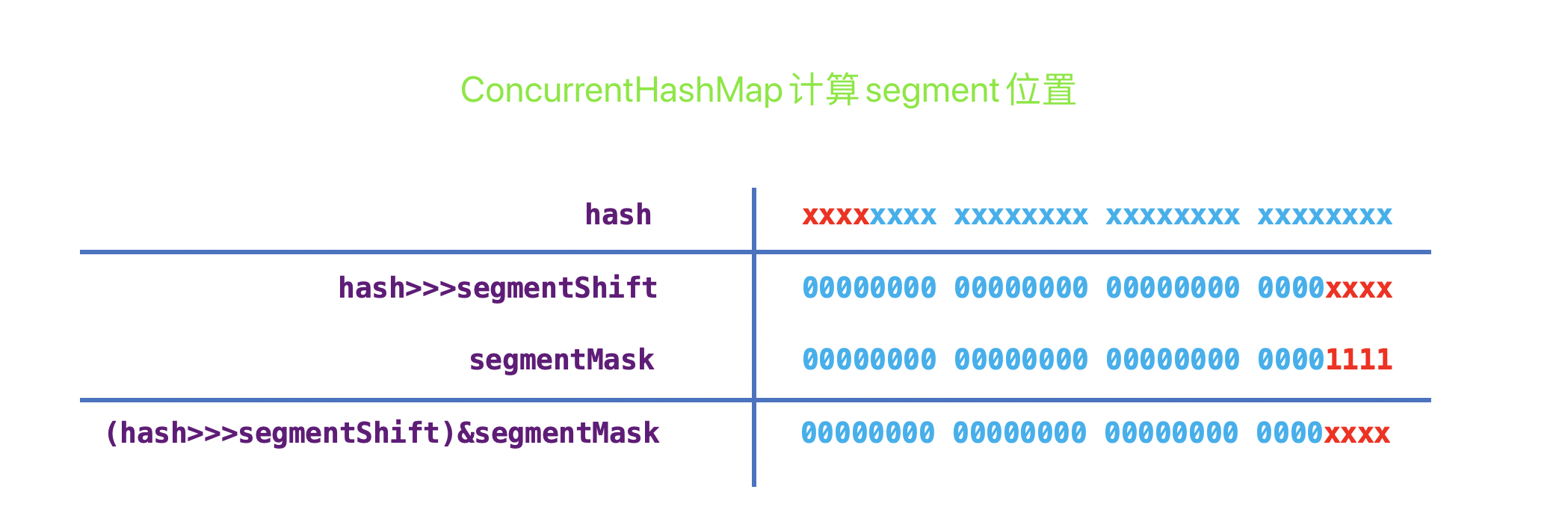
/** * Mask value for indexing into segments. The upper bits of a * key's hash code are used to choose the segment. */ //segmentMask = segment[].length - 1 用来执行【haschCode & segmentMask】计算Hash值 finalint segmentMask;
1 2 3 4 5
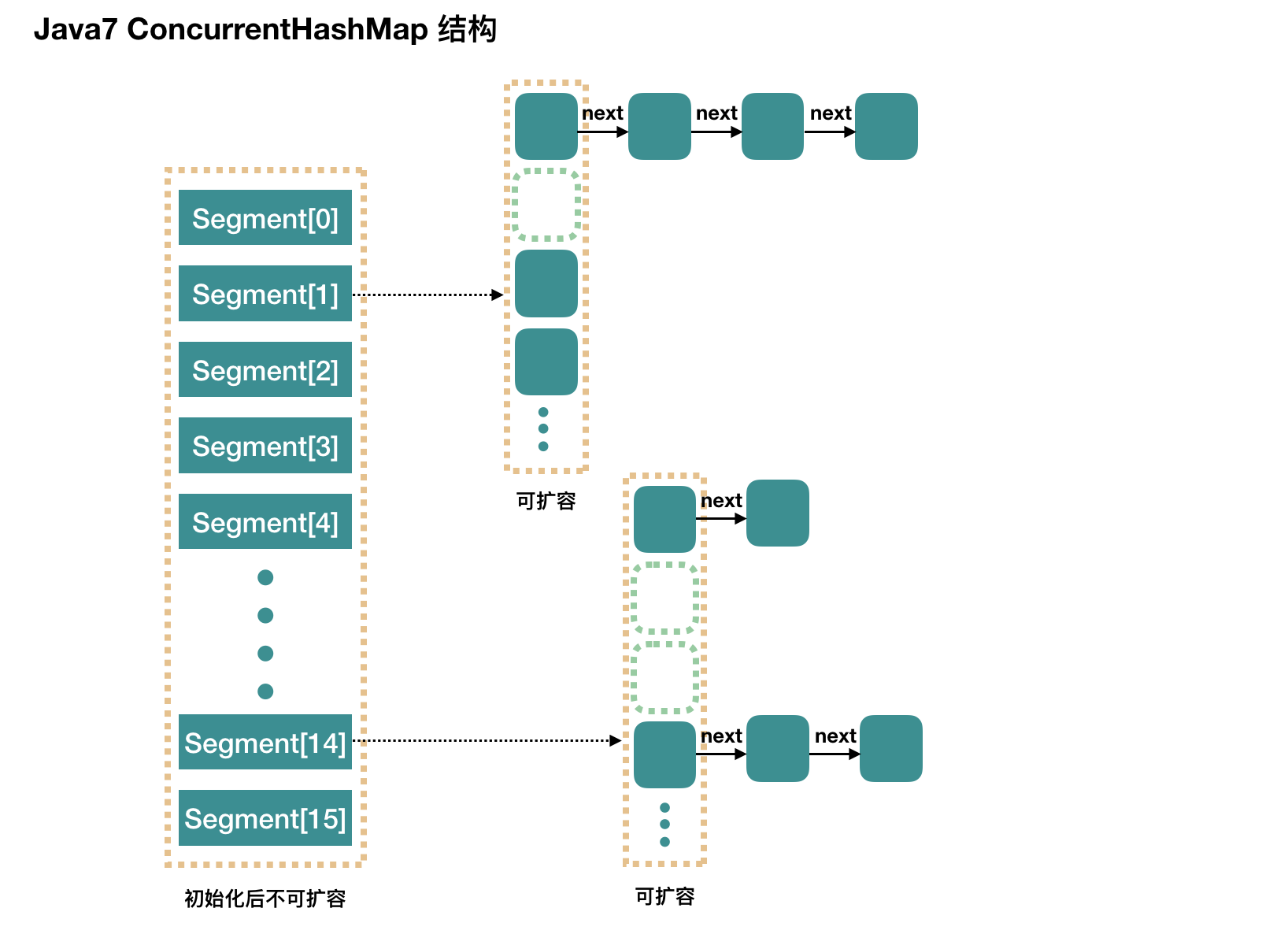
/** * The segments, each of which is a specialized hash table. */ //ConcurrentHashMap的分段锁对象,自身带了一把锁且存储了链表结构 final Segment<K,V>[] segments;
/** * Segments are specialized versions of hash tables. This * subclasses from ReentrantLock opportunistically, just to * simplify some locking and avoid separate construction. */ staticfinalclassSegment<K,V> extendsReentrantLockimplementsSerializable{ /** * The maximum number of times to tryLock in a prescan before * possibly blocking on acquire in preparation for a locked * segment operation. On multiprocessors, using a bounded * number of retries maintains cache acquired while locating * nodes. */ staticfinalint MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
/** * The number of elements. Accessed only either within locks * or among other volatile reads that maintain visibility. */ //HashEntry的数组中的所有HashEntry大小(包括链表) transientint count; //HashEntry数组的变化次数 transientint modCount; //扩容阈值 transientint threshold; //扩容因子 finalfloat loadFactor; }
/** * Scans for a node containing given key while trying to * acquire lock, creating and returning one if not found. Upon * return, guarantees that lock is held. UNlike in most * methods, calls to method equals are not screened: Since * traversal speed doesn't matter, we might as well help warm * up the associated code and accesses as well. * * @return a new node if key not found, else null */ private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value){ //根据Hash值计算数组下标并获取链表的表头 HashEntry<K,V> first = entryForHash(this, hash); HashEntry<K,V> e = first; HashEntry<K,V> node = null; //用这个变量来控制循环的逻辑 int retries = -1; // negative while locating node //循环尝试获取锁 while (!tryLock()) { HashEntry<K,V> f; // to recheck first below if (retries < 0) { //当链表的表头 == null 或者遍历链表后未匹配到元素时,创建HashEntry对象 if (e == null) { if (node == null) // speculatively create node node = new HashEntry<K,V>(hash, key, value, null); //设置retries=0用以下次循环时调用其他逻辑 retries = 0; } //当链表表头不为空时,遍历链表,寻址到链表元素时设置retries=0调用其他逻辑 elseif (key.equals(e.key)) retries = 0; else //当链表遍历到最后一个节点,e.next=null,当再次循环时,会调用创建HashEntry对象的逻辑 e = e.next; } //当重试次数大于一定的次数时,直接调用阻塞的Lock方法 elseif (++retries > MAX_SCAN_RETRIES) { lock(); break; } //(retries & 1) == 0 :当retries是偶数时,返回true,表示每隔一次才去判断链表表头是否发生变化 //重新获取链表表头,当链表表头与原来获取的first不同时,设置retries=-1,重新遍历 elseif ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; // re-traverse if entry changed retries = -1; } } return node; }
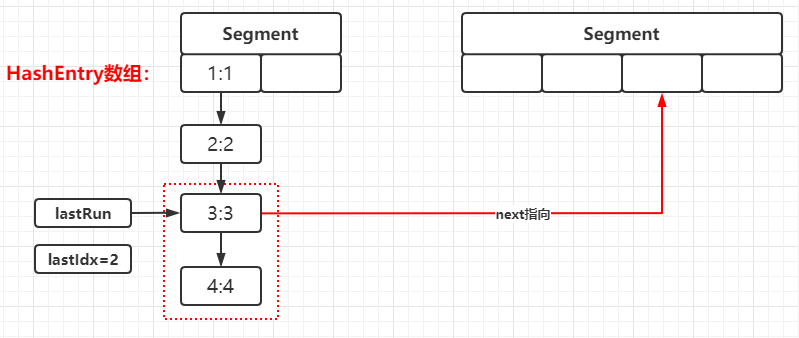
//注意:这里传的参数是新的HashEntry对象,其next属性指向原链表的头部 privatevoidrehash(HashEntry<K,V> node){ HashEntry<K,V>[] oldTable = table; int oldCapacity = oldTable.length; //向左偏移1位,扩容一倍大小 int newCapacity = oldCapacity << 1; //重新计算阈值 threshold = (int)(newCapacity * loadFactor); //初始化新的HashEntry数组 HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity]; //HashEntry[].length - 1 用于计算Hash值 int sizeMask = newCapacity - 1; for (int i = 0; i < oldCapacity ; i++) { //遍历旧的HashEntry数组 HashEntry<K,V> e = oldTable[i]; if (e != null) { HashEntry<K,V> next = e.next; //计算出新的HashEntry数组下标 int idx = e.hash & sizeMask; //当链表中只有一个元素时,直接将该元素赋值到数组中 if (next == null) // Single node on list newTable[idx] = e; else { // Reuse consecutive sequence at same slot HashEntry<K,V> lastRun = e; int lastIdx = idx; //该循环的目的是从链表尾部截取出一条与链表末尾节点的新数组下标相同,并且相连的链表 //并存储该截取链表的头对象到lastRun对象,存储新数组下标到lastIdx中 for (HashEntry<K,V> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } //直接移动尾部截取的链表到新的数组下标中 newTable[lastIdx] = lastRun; // Clone remaining nodes //重新顺着从原链表头开始遍历,遍历到lastRun,也就是链表截取处时,跳出循环 for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; //采用头插法讲一个个元素分别插入到链表头中,并赋值给HashEntry数组 newTable[k] = new HashEntry<K,V>(h, p.key, v, n); } } } } //对原链表扩容完成之后,计算新的HashEntry的下标 int nodeIndex = node.hash & sizeMask; // add the new node //替换链表头 node.setNext(newTable[nodeIndex]); //赋值到HashEntry数组中 newTable[nodeIndex] = node; table = newTable; }
/** * Sets the ith element of given table, with volatile write * semantics. (See above about use of putOrderedObject.) */ staticfinal <K,V> voidsetEntryAt(HashEntry<K,V>[] tab, int i, HashEntry<K,V> e){ UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e); }
publicintsize(){ // Try a few times to get accurate count. On failure due to // continuous async changes in table, resort to locking. final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits long sum; // sum of modCounts long last = 0L; // previous sum int retries = -1; // first iteration isn't retry try { for (;;) { //当重试次数超过2次时,开启加锁计算 if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { //累加各个segment的修改次数 sum += seg.modCount; //累加各个segment的元素数量 int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } //第一次循环:当ConcurrentHashMap的modCount=0时,代表没元素,跳出循环 //第二次循环:和上一次循环计算的元素总数量数比较,如果相同返回,不同则加锁 if (sum == last) break; //第一次循环计算的元素总数量赋值给last last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }