Elasticsearch 之 Painless
Painless
Painless是一种专门用于Elasticsearch的简单,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,安全的脚本语言。它是Elasticsearch的默认脚本语言,可以安全地用于内联和存储脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
POST index/_update/id
{
"script": "ctx._source.price -=1"
}
POST index/_update/id
{
"script": {
"source": "ctx._source.price -=1"
}
}
|
add
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add('无线充电')"
}
}
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add(params.tag_name)",
"params": {
"tag_name": "无线充电"
}
}
}
|
delete
1
2
3
4
5
6
7
8
|
POST product2/_update/15
{
"script": {
"lang": "painless",
"source": "ctx.op='delete'"
}
}
|
upsert
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
GET /product2/_doc/15
POST product2/_update/15
{
"script": {
"source": "ctx._source.price += params.param1",
"lang": "painless",
"params": {
"param1": 100
}
},
"upsert": {
"name": "小米10",
"price": 1999
}
}
|
查询
Elasticsearch首次执行脚本时,将对其进行编译并将编译后的版本存储在缓存中。编译过程比较消耗性能。
如果需要将变量传递到脚本中,则应以命名形式传递变量,params而不是将值硬编码到脚本本身中。例如,如果您希望能够将字段值乘以不同的乘数,请不要将乘数硬编码到脚本中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "painless",
"source": "doc['price'].value * 9"
}
}
}
}
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "expression",
"source": "doc['price'].value * num",
"params": {
"num": 9
}
}
}
}
}
|
doc['price'] * num只编译一次,而doc['price'] * 9 会随着数字改变而一直编译,效率没有传参的方式高效。ES默认每分钟支持15次编译。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
GET product2/_search
{
"script_fields": {
"price": {
"script": {
"lang": "painless",
"source": "doc['price'].value"
}
},
"discount_price": {
"script": {
"lang": "painless",
"source": "[doc['price'].value * params.p1,doc['price'].value * params.p2]",
"params": {
"p1": 0.8,
"p2": 0.7
}
}
}
}
}
|
Stored scripts
Stored scripts :可以理解为script模板 缓存在集群的cache中,默认缓存大小是100MB 没有过期时间 可以手工设置过期时间script.cache.expire 通过script.cache.max_size设置缓存大小 脚本最大64MB 通过script.max_size_in_bytes配置 只有发生变更时重新编译。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
POST _scripts/calculate-discount
{
"script": {
"lang": "painless",
"source": "doc['price'].value * params.discount"
}
}
GET _scripts/calculate-discount
DELETE _scripts/calculate-discount
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
GET product2/_search
{
"script_fields": {
"discount_price": {
"script": {
"id":"calculate-discount",
"params": {
"discount": 0.8
}
}
}
}
}
|
Dates
Dates:ZonedDateTime类型,因此它们支持诸如之类的方法getYear,getDayOfWeek 或例如从历元开始到毫秒getMillis。要在脚本中使用它们,请省略get前缀并继续使用小写的方法名其余部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
GET product2/_search
{
"script_fields": {
"test_year": {
"script": {
"source": "doc.createtime.value.year"
}
}
}
}
|
Groovy
通过两个"""括起来,在里面能够把它当做java代码进行编写,每个语句分隔使用;,支持使用条件语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
ctx._source.name += params.name;
ctx._source.price -= 1
""",
"params": {
"name": "无线充电",
"price": "1"
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
// =~ 部分匹配 name中包含phone [\s\S]表示任意符号
if (ctx._source.name =~ /[\s\S]*phone[\s\S]*/) {
ctx._source.name += "***|";
} else {
//什么都不做
ctx.op = "noop";
}
"""
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
// ==~ 全匹配 日期
if (ctx._source.createtime ==~ /[0-9]{4}-[0-9]{2}-[0-9]{2}/) {
ctx._source.name += "|***";
} else {
ctx.op = "noop";
}
"""
}
}
|
正则表达式默认情况下处于禁用状态,因为他们绕过了Painless的针对长时间运行和占用内存的脚本保护措施,而且有深度堆栈行为,若想要开启,则需要在elasticsearch.yml增加配置:
1
| script.painless.regex.enabled: true
|
聚合操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"lt": 1000
}
}
}
]
}
},
"aggs": {
"tag_agg_group": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0; i < doc['tags.keyword'].length; i++)
{
total++
}
return total;
"""
}
}
}
},
"size": 0
}
|
doc[‘field’].value和params[‘_source’] [‘field’] 的区别:
理解之间的区别是很重要的,首先,使用doc关键字,将导致该字段的条件被加载到内存(缓存),这将导致更快的执行,但更多的内存消耗。
此外,doc[…]符号只允许简单类型(不能返回一个复杂类型(JSON对象或者nested类型)),只有在非分析或单个词条的基础上有意义。
但是,doc如果可能,使用仍然是从文档访问值的推荐方式,因为_source每次使用时都必须加载并解析。使用_source非常缓慢。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
GET /test_index/_search
{
"aggs": {
"sum_person": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0; i < params['_source']['people'].length; i++)
{
if (params['_source']['people'][i]['SF'] == '男') {
total += 1;
}
}
return total;
"""
}
}
}
},
"size": 0
}
|
写入原理
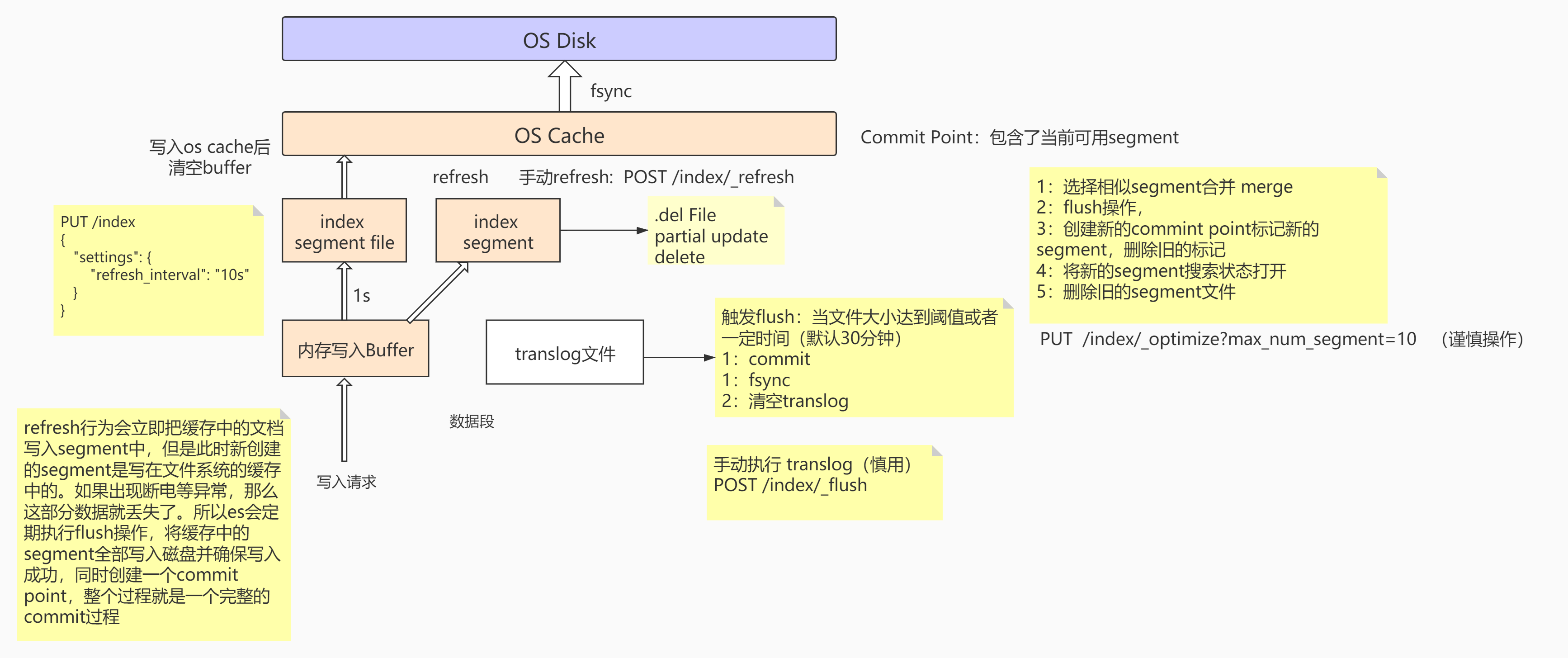
当有写入请求时,数据会先写到内存的Buffer中(Buffer专门用于写入操作),每间隔1S会创建一个index segment的file,然后segment会同步到OS cache中,OS cache会返回一个status = Open,这时候的segment就能对外提供搜索操作。
读写操作进行了异步分离操作,segment对外提供读搜索操作,OS cache后台异步写入数据。
在这种方式下,如果宕机会造成少部分数据的丢失,ES是怎么避免的?
ES在写入索引时,并没有实时落盘到索引文件,而是先双写到内存和translog文件,假如节点挂了,重启节点时就会重放日志,这样相当于把用户的操作模拟了一遍。保证了数据的不丢失。
1
2
3
4
| 当OS cache中的数据达到一定大小之后或者一定时间后,触发Flush:
1.执行 commit操作,把内存中的Buffer、Segment数据同步到OS cache
2.把OS cache的数据fsync到 磁盘中
3.清空translog
|
Commit Point用于存储可用的segment,每当创建一个segment时,都会往Commit point中做登记,segment文件并不是无限制地创建的,当达到一定的操作/大小时,会执行segment合并操作:
1
2
3
4
5
| 1.选择一些体积小的segment,然后将其合并成一个更大的segment
2.执行flush操作,讲OS cache的数据落地到磁盘中
3.创建新的commit point,并且登记新的segment,然后将旧的segment标记成删除状态
4.将新的segment搜索状态`status=open`打开
5.将删除状态的segment文件删除
|
segment维护了一个.del的文件,当有数据执行删除/更新操作时,它会先将数据在segment中标记成删除的状态,这时候没有物理删除,然后在查询的时候,会将删除状态的数据进行过滤。
