JVM
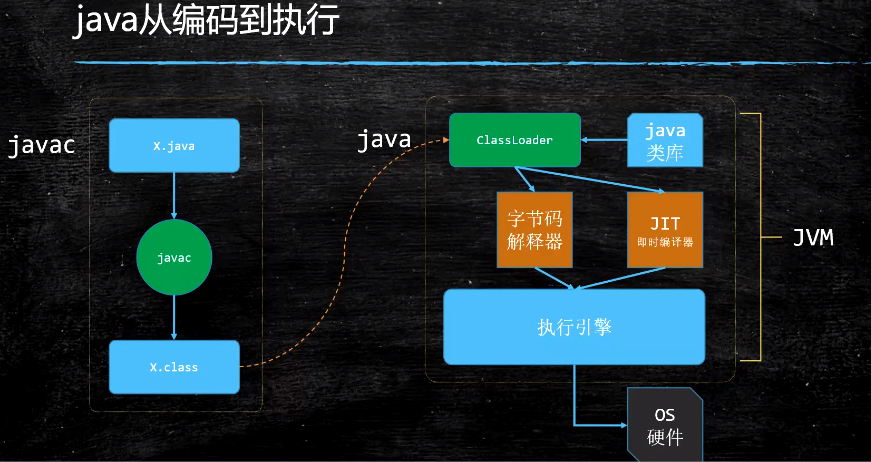
Class格式
Java虚拟机规范规定,Class文件格式采用类似C语言结构体的伪结构来存储数据,这种结构只有两种数据类型:无符号数和表。
无符号数
属于基本数据类型,主要可以用来描述数字、索引符号、数量值或者按照UTF-8编码构成的字符串值,大小使用u1、u2、u4、u8分别表示1字节、2字节、4字节和8字节。
表
是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有的表都习惯以“_info”结尾。表主要用于描述有层次关系的复合结构的数据,比如方法、字段。需要注意的是class文件是没有分隔符的,所以每个的二进制数据类型都是严格定义的。具体的顺序定义如下:
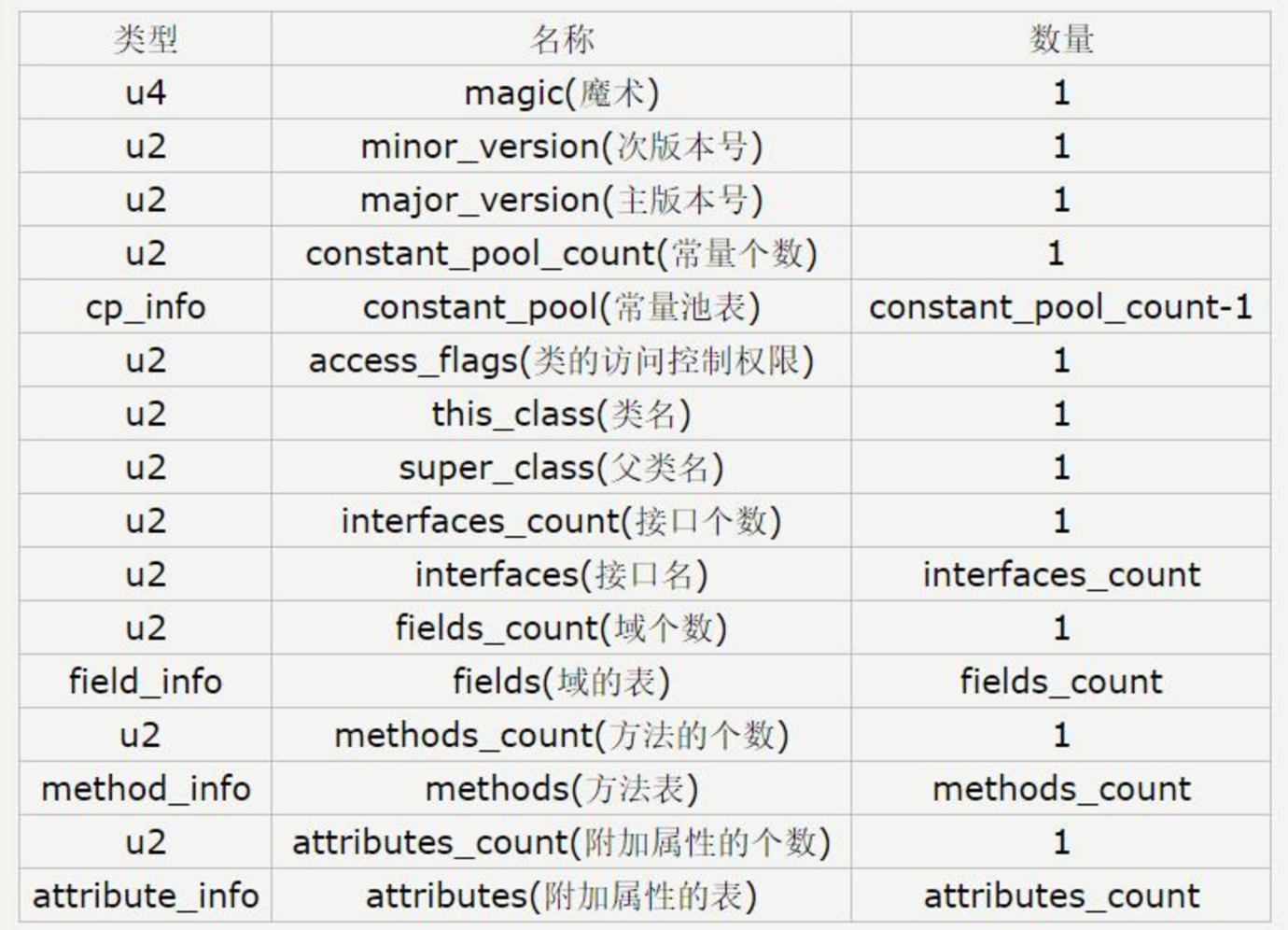
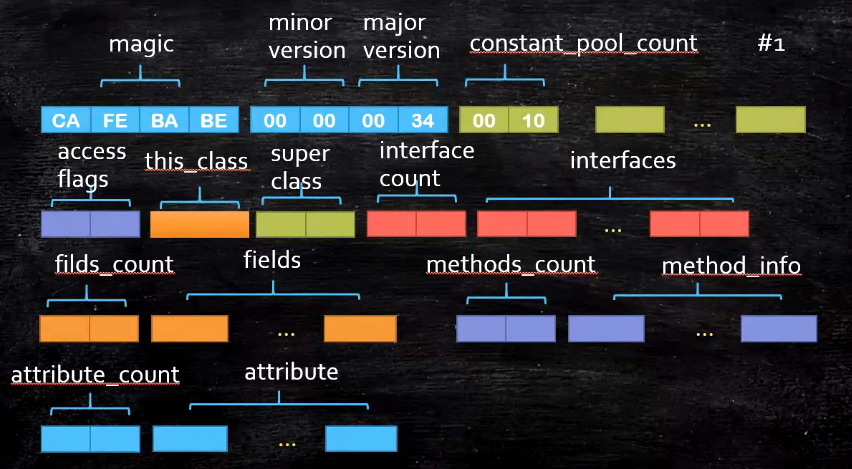
从二进制的数据来看:
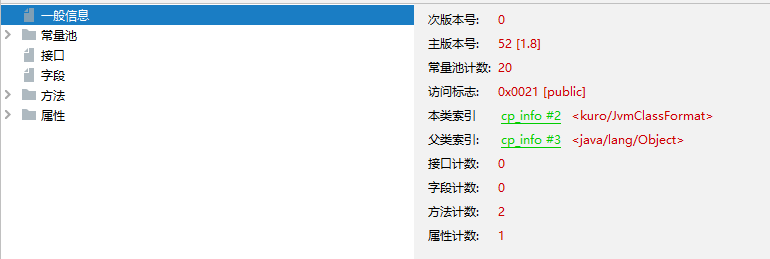
通过javap编译成可视化语言来看:
1 |
|
1 | 魔法数字: cafe babe |
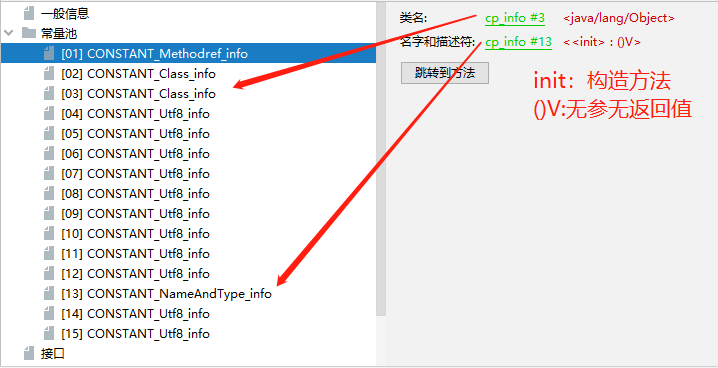
详情可查阅查阅:
类初始化的过程
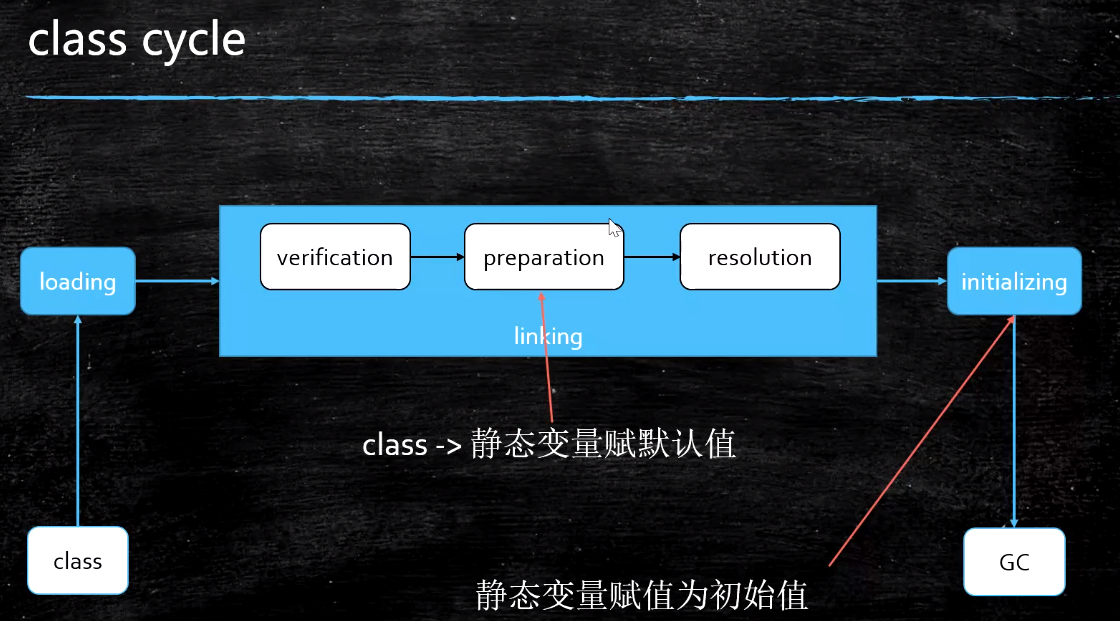
加载
1.通过一个类的全限定名来获取定义此类的二进制字节流。
2.将这个字节流所代表的的静态存储结构转化成访问区的运行时数据结构。
3.在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
验证
文件格式验证、元数据验证、字节码验证、符号引用验证等等。
如验证是否以0xCAFEBABE开头
准备
为类变量分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。
这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配到Java堆中。
正常情况下,这里初始化的值是静态变量的数据类型的默认值,而不是属性指定的值,如果它还被final修饰了,那么将会在这个阶段直接初始化成属性指定的值。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。
初始化
执行类构造器<clinit>()方法,<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,静态语句块中只能访问到定义在静态语句之前的变量。
也就是说,静态属性和静态代码块的赋值和调用在初始化过程中执行,先执行父类的,再执行子类的。
1 | public class T001_ClassLoadingProcedure { |
1 | public class T001_ClassLoadingProcedure { |
如果是
Object o = new Object(),有以下几步:1、申请内存空间,这时候成员变量均是默认值
2、调用构造方法,初始化成员变量值
3、建立栈上和堆内存对象的关联关系
1 | //当我们调用构造方法时,java的底层的字节码指令如下: |
类加载器
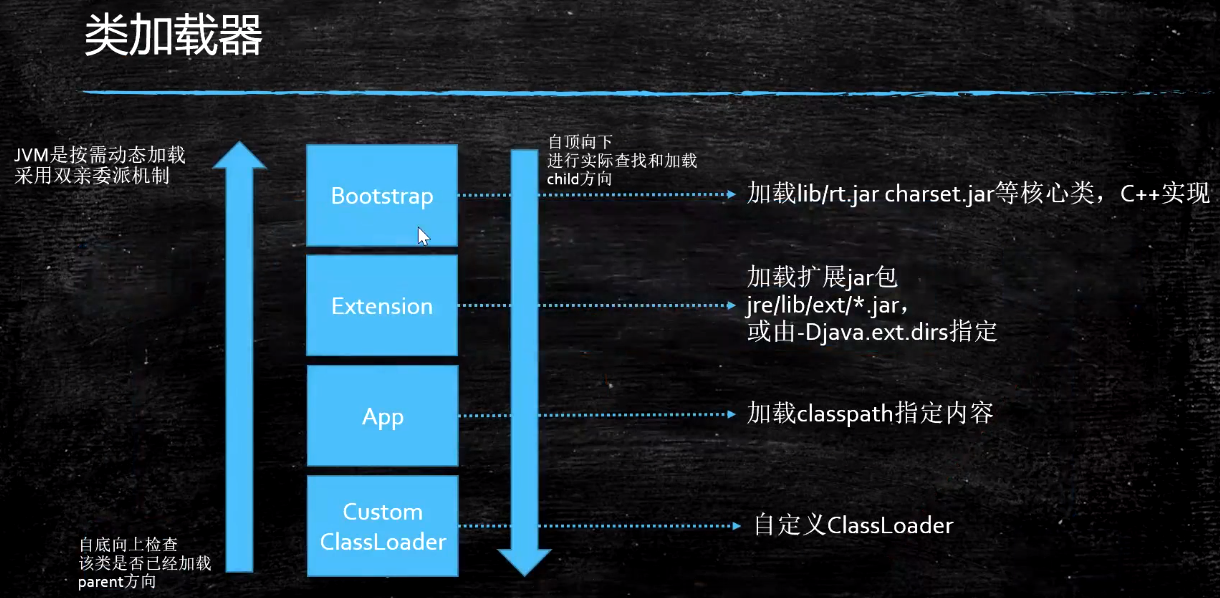
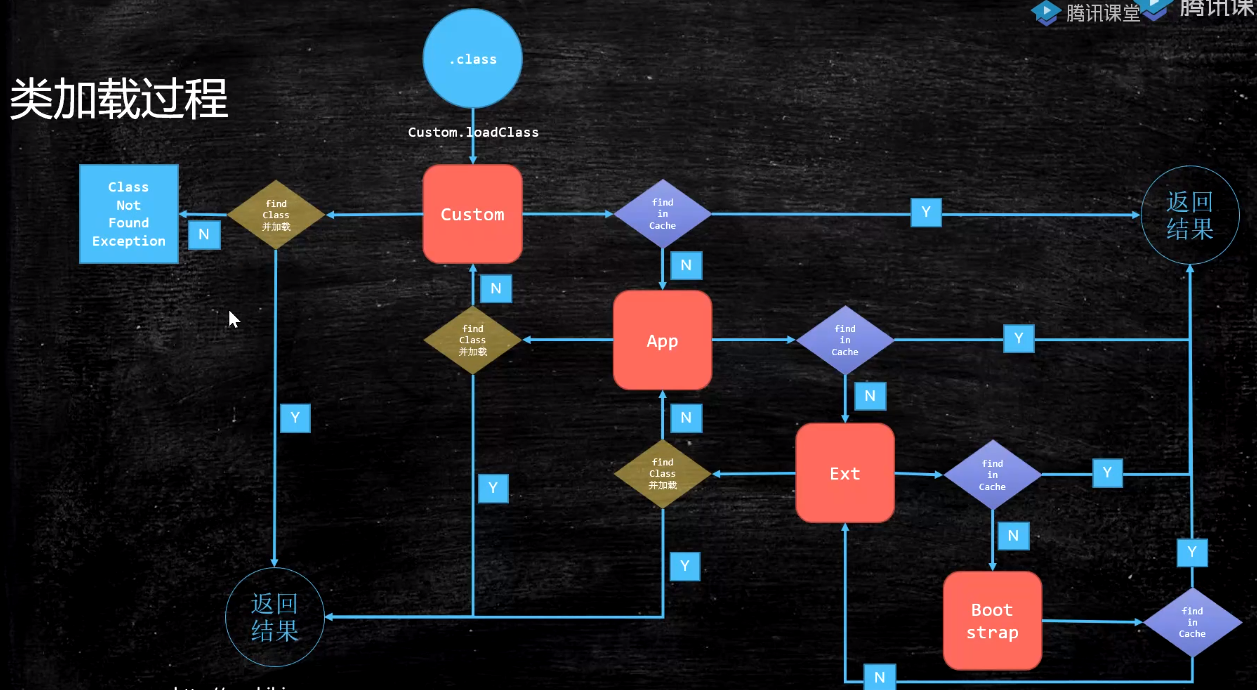
如果一个类加载器收到了类加载的请求,它不会先尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己加载。
这里的父-子是通过使用组合关系,而不是使用继承关系。
父类加载器不是类加载器的加载器,也不是类加载器的父类加载器。双亲委派是一个孩子向父亲方向,然后父亲向孩子方向的双亲委派过程。
为什么用双亲委派机制?
安全,保证了Java程序的稳定运行。避免核心类库被用户覆盖。
查看各个类加载器加载的路径及信息可以查阅Launcher.java
1 | BootStrap ClassLoader:sun.boot.class.path |
JDK破坏双亲委派机制的历史
双亲委派模型的第一次被破坏发生在双亲委派模型出现之前,由于双亲委派模型在JDK1.2之后才被引入,为了向前兼容,JDK1.2之后添加了一个findClass()方法。
双亲委派模型的第二次被破坏是由于模型自身的缺陷导致的,有些标准服务是由启动类加载器(Bootstrap)去加载的,但它又需要调用独立厂商实现并部署在应用程序的ClassPath下的代码,为了解决这个问题,引入了线程上下文类加载器,如果有了线程上下文类加载器,父类加载器将会请求子类加载器去完成类加载动作。
双亲委派模型的第三次被破坏是由于用户对程序动态性的追求导致的。如热替换、热部署。
假设每个程序都有一个自己的类加载器,当需要更换一个代码片段时,就把这个代码片段连同类加载器一起换掉实现代码的热替换。
自定义类加载器的实现是通过继承ClassLoader并复写它的findClass方法即可。若要破坏双亲委派模型,则还需要重写loadClass方法。
1 |
|
编译器和解释器
Java默认采用混合模式,初期通过编译器编译Class文件的代码,当出现热点代码时,会通过JIT解释器把热点代码解释成本地代码,提高运行效率。
1 | # 热点代码的阈值频次 |
内存模型
Synchronized加锁原语、CPU缓存、MESI、缓存行、缓存对齐 详细内容
对象定位
句柄池、直接指针
原语指令
1 | public class Hello_03 { |
上文代码将解析成以下原语指令:
1 | #main方法 |
1 | #m1方法 |
1 | #局部变量表 |
1 | invokeinterface: |
垃圾回收
参数
1 | #小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器 |
1 | 查看默认参数配置 |
标准: - 开头,所有的HotSpot都支持
非标准:-X 开头,特定版本HotSpot支持特定命令
不稳定:-XX 开头,下个版本可能取消
1 | public class HelloGC { |
1 | #区分概念:内存泄漏memory leak,内存溢出out of memory |
调优
- 吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)
- 响应时间:STW越短,响应时间越好
所谓调优,首先确定,追求吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…,吞吐量优先 一般(PS + PO),响应时间 一般(1.8 G1)
什么是调优?
- 根据需求进行JVM规划和预调优
- 优化运行JVM运行环境(慢,卡顿)
- 解决JVM运行过程中出现的各种问题(OOM)
规划调优
调优,从业务场景开始,没有业务场景的调优都是耍流氓
无监控(压力测试,能看到结果),不调优
步骤:
熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS]
预调优
选择回收器组合
计算内存需求(经验值 1.5G 16G)
选定CPU(越高越好)
设定年代大小、升级年龄
设定日志参数(循环5个日志文件,100M)
- -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
- 或者每天产生一个日志文件
观察日志情况
预调优
QPS:一秒内查询的并发量 TPS:一秒内业务的并发量
案例1:垂直电商,最高每日百万订单,处理订单系统需要什么样的服务器配置?
这个问题比较业余,因为很多不同的服务器配置都能支撑(1.5G 16G)
1小时360000集中时间段, 100个订单/秒,(找一小时内的高峰期,1000订单/秒)
经验值,
非要计算:一个订单产生需要多少内存?512K * 1000 500M内存
专业一点儿问法:要求响应时间100ms
压测!
案例2:12306遭遇春节大规模抢票应该如何支撑?
12306应该是中国并发量最大的秒杀网站:
号称并发量100W最高
CDN -> LVS -> NGINX -> 业务系统 -> 每台机器1W并发(10K问题) 100台机器
普通电商订单 -> 下单 ->订单系统(IO)减库存 ->等待用户付款
12306的一种可能的模型: 下单 -> 减库存 和 订单(redis kafka) 同时异步进行 ->等付款
减库存最后还会把压力压到一台服务器
可以做分布式本地库存 + 单独服务器做库存均衡
大流量的处理方法:分而治之
怎么得到一个事务会消耗多少内存?
- 弄台机器,看能承受多少TPS?是不是达到目标?扩容或调优,让它达到
- 用压测来确定
优化环境
有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G 的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G 的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了
1 | 1.为什么原网站慢? |
系统CPU经常100%,如何调优?
1 | **CPU100%那么一定有线程在占用系统资源** |
系统内存飙高,如何查找问题?
1 | 1. 导出堆内存 (jmap) |
如何监控JVM?
jstat jvisualvm jprofiler arthas top…
jstack
1 | jstack |
1 | [root@localhost ~]# jstack -l <pid> |
两个线程都互相等待锁信息,死锁。
1 | "Thread-1": |
案例
1 | /** |
1 | 1.java -Xms200M -Xmx200M -XX:+PrintGC T15_FullGC_Problem01 |
远程连接
jconsole远程服务器程序,程序启动需要增加以下参数:
1 | java -Djava.rmi.server.hostname=192.168.17.11 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=11111 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false XXX |
案例汇总
OOM产生的原因多种多样,有些程序未必产生OOM,不断FGC(CPU飙高,但内存回收特别少) (上面案例)
硬件升级系统反而卡顿的问题(见上)
线程池不当运用产生OOM问题(见上)
tomcat http-header-size过大问题
lambda表达式导致方法区溢出问题(MethodArea / Perm Metaspace)
1
2
3
4
5
6
7
8java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.instrument.InstrumentationImpl.loadClassAndStartAgent(InstrumentationImpl.java:388)
at sun.instrument.InstrumentationImpl.loadClassAndCallAgentmain(InstrumentationImpl.java:411)
Caused by: java.lang.OutOfMemoryError: Compressed class space栈溢出问题 -Xss设定太小
比较一下这两段程序的异同,分析哪一个是更优的写法:
1
2
3
4
5
6
7
8Object o = null;
for(int i=0; i<100; i++) {
o = new Object();
//业务处理
}
for(int i=0; i<100; i++) {
Object o = new Object();
}重写finalize引发频繁GC 小米云,HBase同步系统,系统通过nginx访问超时报警,最后排查,C++程序员重写finalize引发频繁GC问题 为什么C++程序员会重写finalize?(new delete) finalize耗时比较长(200ms)
如果有一个系统,内存一直消耗不超过10%,但是观察GC日志,发现FGC总是频繁产生,会是什么引起的? System.gc()
参数汇总
GC常用参数
- -Xmn -Xms -Xmx -Xss 年轻代 最小堆 最大堆 栈空间
- -XX:+UseTLAB 使用TLAB,默认打开
- -XX:+PrintTLAB 打印TLAB的使用情况
- -XX:TLABSize 设置TLAB大小
- -XX:+DisableExplictGC System.gc()不管用 ,FGC
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintHeapAtGC
- -XX:+PrintGCTimeStamps
- -XX:+PrintGCApplicationConcurrentTime (低) 打印应用程序时间
- -XX:+PrintGCApplicationStoppedTime (低) 打印暂停时长
- -XX:+PrintReferenceGC (重要性低) 记录回收了多少种不同引用类型的引用
- -verbose:class 类加载详细过程
- -XX:+PrintVMOptions
- -XX:+PrintFlagsFinal -XX:+PrintFlagsInitial 必须会用
- -Xloggc:opt/log/gc.log
- -XX:MaxTenuringThreshold 升代年龄,最大值15
- 锁自旋次数 -XX:PreBlockSpin 热点代码检测参数-XX:CompileThreshold 逃逸分析 标量替换 … 这些不建议设置
Parallel常用参数
- -XX:SurvivorRatio
- -XX:PreTenureSizeThreshold 大对象到底多大
- -XX:MaxTenuringThreshold
- -XX:+ParallelGCThreads 并行收集器的线程数,同样适用于CMS,一般设为和CPU核数相同
- -XX:+UseAdaptiveSizePolicy 自动选择各区大小比例
CMS常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads CMS线程数量
- -XX:CMSInitiatingOccupancyFraction 使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收)
- -XX:+UseCMSCompactAtFullCollection 在FGC时进行压缩
- -XX:CMSFullGCsBeforeCompaction 多少次FGC之后进行压缩
- -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction 达到什么比例时进行Perm回收
- GCTimeRatio 设置GC时间占用程序运行时间的百分比
- -XX:MaxGCPauseMillis 停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis 建议值,G1会尝试调整Young区的块数来达到这个值
- -XX:GCPauseIntervalMillis ?GC的间隔时间
- -XX:+G1HeapRegionSize 分区大小,建议逐渐增大该值,1 2 4 8 16 32。 随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长 ZGC做了改进(动态区块大小)
- G1NewSizePercent 新生代最小比例,默认为5%
- G1MaxNewSizePercent 新生代最大比例,默认为60%
- GCTimeRatio GC时间建议比例,G1会根据这个值调整堆空间
- ConcGCThreads 线程数量
- InitiatingHeapOccupancyPercent 启动G1的堆空间占用比例
最后更新: 2020年12月21日 21:15
