publicclassT11_TestSemaphore{ publicstaticvoidmain(String[] args){ //Semaphore s = new Semaphore(2); Semaphore s = new Semaphore(2, true); //允许一个线程同时执行 //Semaphore s = new Semaphore(1);
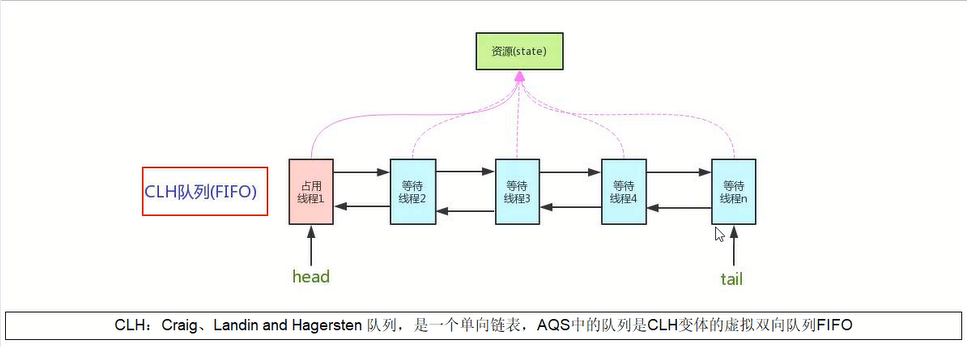
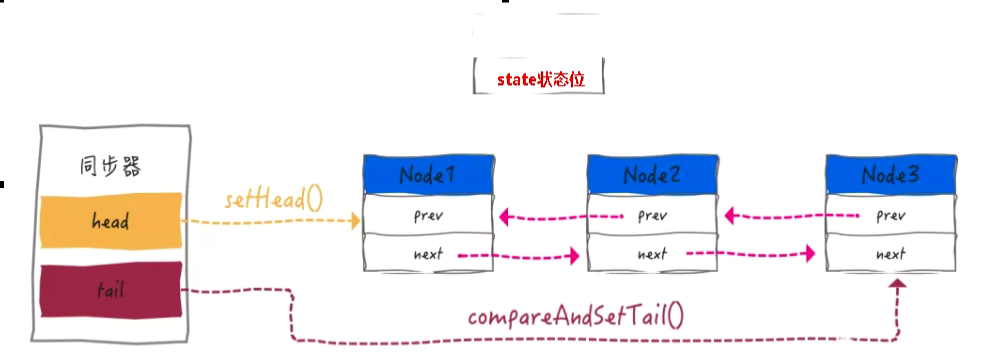
/** * Head of the wait queue, lazily initialized. Except for * initialization, it is modified only via method setHead. Note: * If head exists, its waitStatus is guaranteed not to be * CANCELLED. */ //CLH的头节点 privatetransientvolatile Node head;
/** * Tail of the wait queue, lazily initialized. Modified only via * method enq to add new wait node. */ //CLH的尾节点 privatetransientvolatile Node tail;
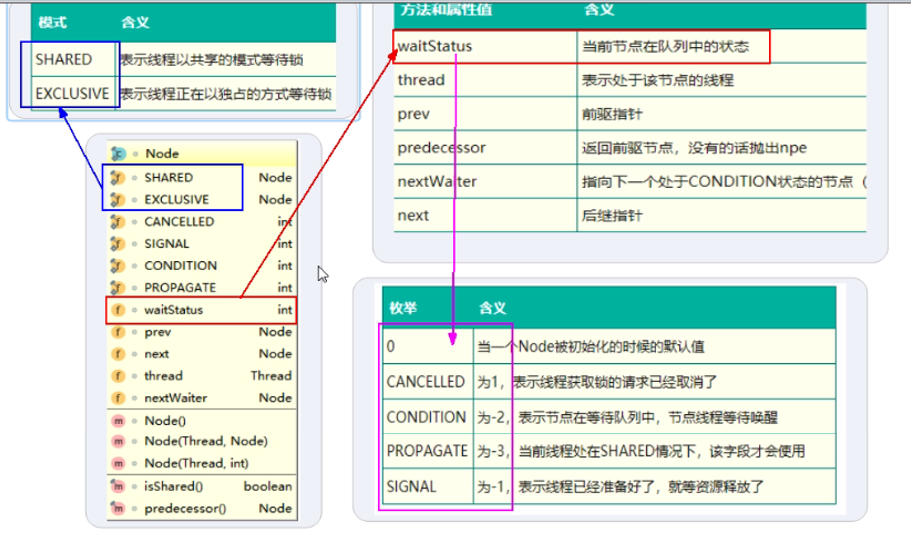
/** * The thread that enqueued this node. Initialized on * construction and nulled out after use. */ volatile Thread thread;
/** * Link to next node waiting on condition, or the special * value SHARED. Because condition queues are accessed only * when holding in exclusive mode, we just need a simple * linked queue to hold nodes while they are waiting on * conditions. They are then transferred to the queue to * re-acquire. And because conditions can only be exclusive, * we save a field by using special value to indicate shared * mode. */ Node nextWaiter;
/** * Returns true if node is waiting in shared mode. */ finalbooleanisShared(){ return nextWaiter == SHARED; } }
int ws = node.waitStatus; if (ws < 0) //重新将node的waitStatus设置成0 compareAndSetWaitStatus(node, ws, 0);
//获取node的后继节点 Node s = node.next; //如果它的后继节点为空或者处于CANCELLED状态 if (s == null || s.waitStatus > 0) { s = null; //从尾部递归找一个waitStatus < 0的节点 for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } //如果节点不为空,那么它必然是waitStatus < 0的,这时候调用unpark唤醒该线程 if (s != null) LockSupport.unpark(s.thread); }
/** * The entries in this hash map extend WeakReference, using * its main ref field as the key (which is always a * ThreadLocal object). Note that null keys (i.e. entry.get() * == null) mean that the key is no longer referenced, so the * entry can be expunged from table. Such entries are referred to * as "stale entries" in the code that follows. */ staticclassEntryextendsWeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value;
@FunctionalInterface publicinterfaceCallable<V> { /** * Computes a result, or throws an exception if unable to do so. * * @return computed result * @throws Exception if unable to compute a result */ V call()throws Exception; }
/** * Attempts to cancel execution of this task. This attempt will * fail if the task has already completed, has already been cancelled, * or could not be cancelled for some other reason. If successful, * and this task has not started when {@code cancel} is called, * this task should never run. If the task has already started, * then the {@code mayInterruptIfRunning} parameter determines * whether the thread executing this task should be interrupted in * an attempt to stop the task. * * <p>After this method returns, subsequent calls to {@link #isDone} will * always return {@code true}. Subsequent calls to {@link #isCancelled} * will always return {@code true} if this method returned {@code true}. * * @param mayInterruptIfRunning {@code true} if the thread executing this * task should be interrupted; otherwise, in-progress tasks are allowed * to complete * @return {@code false} if the task could not be cancelled, * typically because it has already completed normally; * {@code true} otherwise */ booleancancel(boolean mayInterruptIfRunning);
/** * Returns {@code true} if this task was cancelled before it completed * normally. * * @return {@code true} if this task was cancelled before it completed */ booleanisCancelled();
/** * Returns {@code true} if this task completed. * * Completion may be due to normal termination, an exception, or * cancellation -- in all of these cases, this method will return * {@code true}. * * @return {@code true} if this task completed */ booleanisDone();
/** * Waits if necessary for the computation to complete, and then * retrieves its result. * * @return the computed result * @throws CancellationException if the computation was cancelled * @throws ExecutionException if the computation threw an * exception * @throws InterruptedException if the current thread was interrupted * while waiting */ V get()throws InterruptedException, ExecutionException;
/** * Waits if necessary for at most the given time for the computation * to complete, and then retrieves its result, if available. * * @param timeout the maximum time to wait * @param unit the time unit of the timeout argument * @return the computed result * @throws CancellationException if the computation was cancelled * @throws ExecutionException if the computation threw an * exception * @throws InterruptedException if the current thread was interrupted * while waiting * @throws TimeoutException if the wait timed out */ V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
publicinterfaceRunnableFuture<V> extendsRunnable, Future<V> { /** * Sets this Future to the result of its computation * unless it has been cancelled. */ voidrun(); }
publicThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
//案例 ThreadPoolExecutor tpe = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(4), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy());
Executors
SingleThreadExecutor
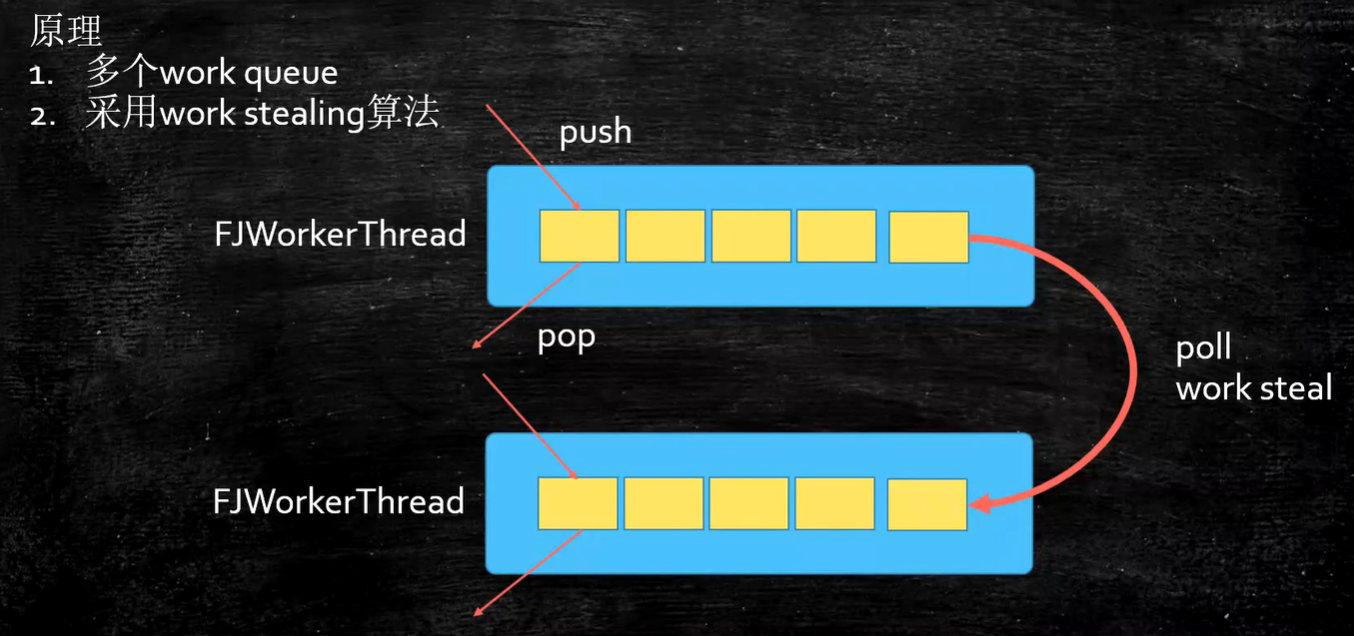
为什么有单线程池?
任务队列、线程池生命周期
1 2 3 4 5 6
publicstatic ExecutorService newSingleThreadExecutor(){ returnnew FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
// Packing and unpacking ctl // 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0 privatestaticintrunStateOf(int c){ return c & ~CAPACITY; } // 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0 privatestaticintworkerCountOf(int c){ return c & CAPACITY; } // 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值 privatestaticintctlOf(int rs, int wc){ return rs | wc; }
/* * Bit field accessors that don't require unpacking ctl. * These depend on the bit layout and on workerCount being never negative. */ // 8. `runStateLessThan()`,线程池状态小于xx privatestaticbooleanrunStateLessThan(int c, int s){ return c < s; } // 9. `runStateAtLeast()`,线程池状态大于等于xx privatestaticbooleanrunStateAtLeast(int c, int s){ return c >= s; }
/** * The queue used for holding tasks and handing off to worker * threads. We do not require that workQueue.poll() returning * null necessarily means that workQueue.isEmpty(), so rely * solely on isEmpty to see if the queue is empty (which we must * do for example when deciding whether to transition from * SHUTDOWN to TIDYING). This accommodates special-purpose * queues such as DelayQueues for which poll() is allowed to * return null even if it may later return non-null when delays * expire. */ //线程池工作队列 privatefinal BlockingQueue<Runnable> workQueue;
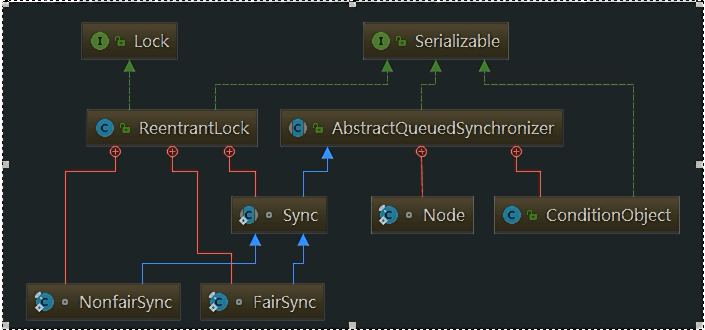
/** * Lock held on access to workers set and related bookkeeping. * While we could use a concurrent set of some sort, it turns out * to be generally preferable to use a lock. Among the reasons is * that this serializes interruptIdleWorkers, which avoids * unnecessary interrupt storms, especially during shutdown. * Otherwise exiting threads would concurrently interrupt those * that have not yet interrupted. It also simplifies some of the * associated statistics bookkeeping of largestPoolSize etc. We * also hold mainLock on shutdown and shutdownNow, for the sake of * ensuring workers set is stable while separately checking * permission to interrupt and actually interrupting. */ //线程池内部的Lock锁,用于Workers集合的变更加锁 privatefinal ReentrantLock mainLock = new ReentrantLock();
/** * Set containing all worker threads in pool. Accessed only when */ //线程池工作线程集合 privatefinal HashSet<Worker> workers = new HashSet<Worker>();
publicvoidexecute(Runnable command){ if (command == null) thrownew NullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */ int c = ctl.get(); // worker数量比核心线程数小,直接创建worker执行任务 if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // worker数量超过核心线程数,任务直接进入队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。 // 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。 if (! isRunning(recheck) && remove(command)) reject(command); // 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0 elseif (workerCountOf(recheck) == 0) //给线程池至少创建一个线程(非核心线程) addWorker(null, false); } // 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。 // 这儿有3点需要注意: // 1. 线程池不是运行状态时,addWorker内部会判断线程池状态 // 2. addWorker第2个参数表示是否创建核心线程 // 3. addWorker返回false,则说明任务执行失败,需要执行reject操作 elseif (!addWorker(command, false)) reject(command); }
/* * Methods for creating, running and cleaning up after workers */
/** * Checks if a new worker can be added with respect to current * pool state and the given bound (either core or maximum). If so, * the worker count is adjusted accordingly, and, if possible, a * new worker is created and started, running firstTask as its * first task. This method returns false if the pool is stopped or * eligible to shut down. It also returns false if the thread * factory fails to create a thread when asked. If the thread * creation fails, either due to the thread factory returning * null, or due to an exception (typically OutOfMemoryError in * Thread.start()), we roll back cleanly. * * @param firstTask the task the new thread should run first (or * null if none). Workers are created with an initial first task * (in method execute()) to bypass queuing when there are fewer * than corePoolSize threads (in which case we always start one), * or when the queue is full (in which case we must bypass queue). * Initially idle threads are usually created via * prestartCoreThread or to replace other dying workers. * * @param core if true use corePoolSize as bound, else * maximumPoolSize. (A boolean indicator is used here rather than a * value to ensure reads of fresh values after checking other pool * state). * @return true if successful */
if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl //重新获取线程池状态,变化则继续执行外层循环,否则继续执行内层循环 if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } }
//表示创建的worker是否已经启动,false未启动 true启动 boolean workerStarted = false; //表示创建的worker是否添加到池子中了 默认false 未添加 true是添加。 boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); final Thread t = w.thread;
//为什么要做 t != null 这个判断? //为了防止ThreadFactory 实现类有bug,因为ThreadFactory 是一个接口,谁都可以实现。 //万一哪个 小哥哥 脑子一热,有bug,创建出来的线程 是null、、 //Doug lea考虑的比较全面。肯定会防止他自己的程序报空指针,所以这里一定要做! if (t != null) { //worker的添加必须得是串行的,因此需要加锁 final ReentrantLock mainLock = this.mainLock; //持有全局锁,可能会阻塞,直到获取成功为止,同一时刻 操纵 线程池内部相关的操作,都必须持锁。 mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get());
//Worker本身是一个Runnable,并且继承了AQS,自身就是一把锁,防止多个线程同时争抢同一个Worker privatefinalclassWorker extendsAbstractQueuedSynchronizer implementsRunnable { /** * This class will never be serialized, but we provide a * serialVersionUID to suppress a javac warning. */ privatestaticfinallong serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */ final Thread thread; /** Initial task to run. Possibly null. */ Runnable firstTask; /** Per-thread task counter */ volatilelong completedTasks;
/** * Creates with given first task and thread from ThreadFactory. * @param firstTask the first task (null if none) */ Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; // 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker this.thread = getThreadFactory().newThread(this); }
/** Delegates main run loop to outer runWorker */ publicvoidrun(){ runWorker(this); }
System.out.println("---" + Arrays.stream(nums).sum()); //stream api }
staticclassAddTaskextendsRecursiveAction{
int start, end;
AddTask(int s, int e) { start = s; end = e; }
@Override protectedvoidcompute(){
if(end-start <= MAX_NUM) { long sum = 0L; for(int i=start; i<end; i++) sum += nums[i]; System.out.println("from:" + start + " to:" + end + " = " + sum); } else {
int middle = start + (end-start)/2;
AddTask subTask1 = new AddTask(start, middle); AddTask subTask2 = new AddTask(middle, end); subTask1.fork(); subTask2.fork(); }
}
}
staticclassAddTaskRetextendsRecursiveTask<Long> {
privatestaticfinallong serialVersionUID = 1L; int start, end;
AddTaskRet(int s, int e) { start = s; end = e; }
@Override protected Long compute(){
if(end-start <= MAX_NUM) { long sum = 0L; for(int i=start; i<end; i++) sum += nums[i]; return sum; }
int middle = start + (end-start)/2;
AddTaskRet subTask1 = new AddTaskRet(start, middle); AddTaskRet subTask2 = new AddTaskRet(middle, end); subTask1.fork(); subTask2.fork();
return subTask1.join() + subTask2.join(); }
}
publicstaticvoidmain(String[] args)throws IOException { /*ForkJoinPool fjp = new ForkJoinPool(); AddTask task = new AddTask(0, nums.length); fjp.execute(task);*/
T12_ForkJoinPool temp = new T12_ForkJoinPool();
ForkJoinPool fjp = new ForkJoinPool(); AddTaskRet task = new AddTaskRet(0, nums.length); fjp.execute(task); long result = task.join(); System.out.println(result);