MyCat
数据切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库上面,以达到分散单台设备负载的效果。
数据的切分根据其切分规则的类型,可以分为两种切分模式:
一种是按照不同的表来切分到不同的数据库之上,这种切可以称之为数据的垂直切分或者纵向切分。
另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上面,这种切分称之为数据的水平切分或者横向切分。
垂直切分的最大特点就是 规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也很小,拆分规则也会比较简单清晰。
水平切分与垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表明来拆分更为复杂,后期的数据维护也会更为复杂一些。
垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者压力分担到不同的库上面。
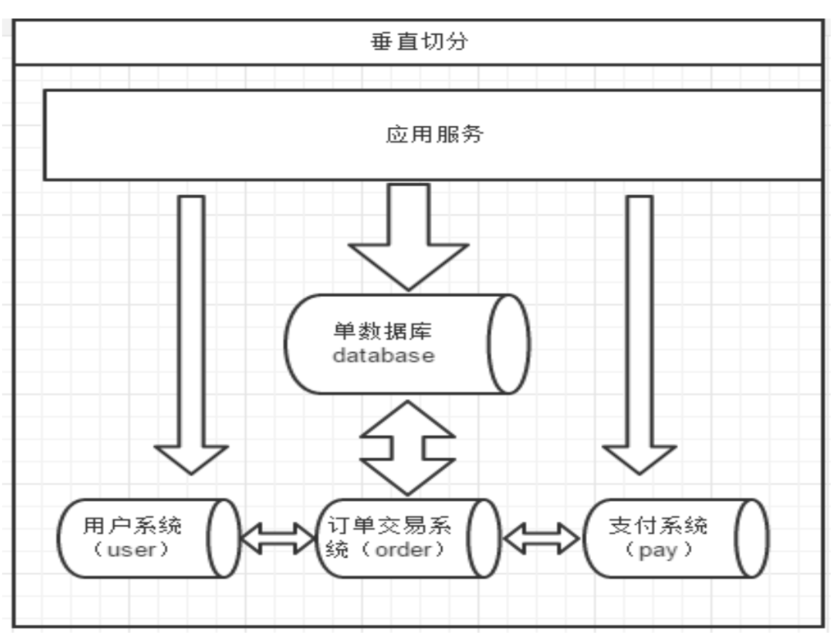
一个架构设计较好的应用系统,其总体功能肯定是又多个功能模块所组成的。而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相关质检的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。
但是往往系统中有些表难以做到完全的独立,存在着跨库join的情况,对于这类的表,就需要去做平衡,是数据让步业务,共用一个数据源还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到一定规模,负载很大的情况下就必须要做分割。
1 | 优点: |
水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,
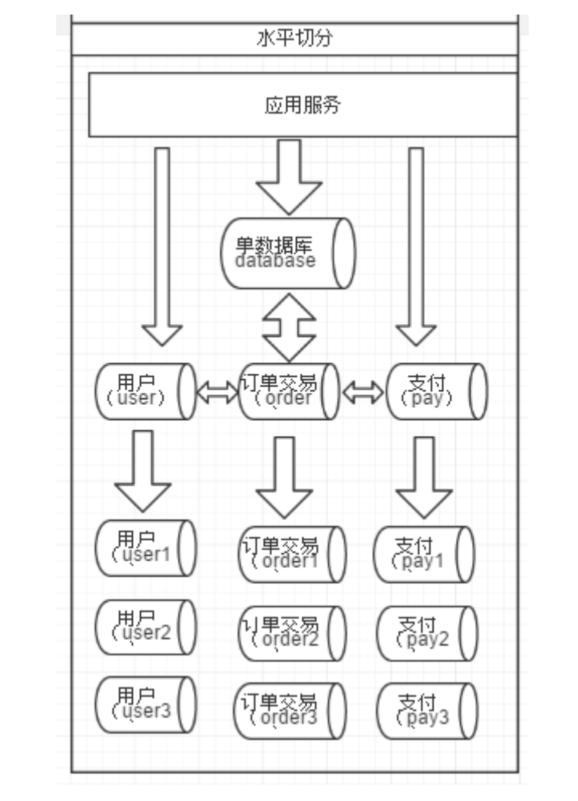
分库
1 |
|
1 | #启动mycat的服务 |
1 | --客户表 |
执行上述的建表语句,会发现,customer在node03上,而其他的表在node01上,此时完成了分库的功能。
在插入完成之后会发现,有的表名是大写的,有的表名是大写的,大家需要注意,这个是一个小问题,需要在mysql的配置文件my.cnf中添加lower_case_table_names=1参数,来保证查询的时候能够进行正常的查询。
若添加表出现分库效果不生效,可以验证一下,是否两个库开启了主从同步的功能。
分表
取模运算
拆分orders表,在进行拆分的时候必须要指定拆分规则,在此实例中,我们选择把customer_id按照取模运算进行数据拆分
1 | <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> <table name = "customer" dataNode="dn2"></table> |
1 | <!-- rule.xml 配置文件 --> |
1 | #重启MyCAT |
分片枚举
通过在配置文件中配置可能存在的值,配置分片。
1 | <!-- schedule.xml --> |
1 | <tableRule name="sharding_by_intfile"> |
1 | #修改partition-hash-int.txt文件 |
1 | #重启MYCAT,创建表,执行语句 |
范围分片
根据分片字段,约定好属于哪一个范围
1 | <!-- schedule.xml --> |
1 | <!-- rule.xml --> |
1 | #修改autopartition-long.txt文件 |
1 | #重启MYCAT,创建表,执行语句 |
范围求模
该算法为先进行范围分片,计算出分片组,组内再求模,综合了范围分片和求模分片的优点。分片组内使用求模可以保证组内的数据分步比较均匀,分片组之间采用范围分片可以兼顾范围分片的特点。事先规定好分片的数量,数据扩容时按分片组扩容,则原有分片组的数据不需要迁移。由于分片组内的数据分步比较均匀,所以分片组内可以避免热点数据问题。
1 | #在node01,node03创建表person |
1 | <table name="person" primaryKey="id" dataNode="dn1,dn2" rule="auto-sharding-rang-mod" |
1 | <tableRule name="auto-sharding-rang-mod"> |
1 | #编辑 partition-range-mod.txt |
1 | #重启MYCAT |
当插入的数据范围超过我们给定的范围之后,会插入到默认节点中
1 | insert into person(id,name) values(25000,'zhangsan0'); |
当使用这种分片规则的时候,还可以进行扩容操作:
1 | create database test; |
1 | CREATE TABLE `person` ( |
1 |
|
1 | #编辑 partition-range-mod.txt |
1 | insert into person(id,name) values(9999,'zhangsan1'); |
可以看到9999和1000被分配到不同的节点上了。
固定分片
类似于十进制的求模运算,但是为二进制的操作,取id的二进制低10位,即id二进制&1111111111.
此算法的优点在于如果按照十进制取模运算,则在连续插入110时,110会被分到1~10个分片,增大了插入事务的控制难度。而此算法根据二进制则可能会分到连续的分片,降低了插入事务的控制难度。
1 | CREATE TABLE `user` ( |
1 | <table name="user" primaryKey="id" dataNode="dn1,dn2,dn3" rule="rule1"></table> |
1 | <!-- |
1 | insert into user(id,name) values(1023,'zhangsan1'); |
可以看到结果,1024,255在一个数据分片,266在一个数据分片,1023在一个数据分片。
如果超过了1024的值,会进行取模,让他总是落在1024的范围上。
取模范围
他是一种先取模,再划分范围的算法,而范围求模是先划分范围,再求模的算法。
1 | CREATE TABLE `user2` ( |
1 | <table name="user2" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern"></table> |
1 | <!-- |
1 | #修改partition-pattern.txt |
1 | insert into user2(id,name) values(85,'zhangsan1'); |
可以看到结果不同的记录被分散到不同的数据分片上。
字符串hash求模
与取模范围算法类似,该算法支持数值、符号、字母取模,此方式就是将指定位数的字符的ascll码的和进行取模运算
1 | CREATE TABLE `user3` ( |
1 | <table name="user3" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-prefixpattern"></table> |
1 | <!-- |
1 | # 修改partition-pattern.txt |
1 | insert into user3(id,name) values(1,'zhangsan'); |
可以看到数据被分散了,但是因为ascll码值是需要计算的,所以结果可能不是很明显。
应用指定
在运行阶段由应用程序自主决定路由到哪个分片
1 | CREATE TABLE `user4` ( |
1 | <table name="user4" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-substring"></table> |
1 | <!-- |
1 | insert into user4(id,name) values(1,'0-zhangsan'); |
可以看到数据被分片存储了。
字符串hash解析
字符串hash解析分片,其实就是根据配置的hash预算位规则,将截取的字符串进行hash计算后,得到的int数值即为datanode index(分片节点索引,从0开始)。
1 | CREATE TABLE `user5` ( |
1 | <table name="user5" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-stringhash"></table> |
1 | <!-- |
1 | insert into user5(id,name) values(1111111,database()); |
日期范围
按照某个指定的日期进行分片
1 | <table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table> |
1 | <tableRule name="sharding_by_date"> |
1 | CREATE TABLE login_info |
按单月小时分片
此规则是单月内按照小时拆分,最小粒度是小时,可以一天最多24个分片,最少一个分片,一个月完成后下个月开始循环,每个月月尾,需要手工清理数据。
1 | <table name="user6" dataNode="dn1,dn2,dn3" rule="sharding-by-hour"></table> |
1 | <tableRule name="sharding-by-hour"> |
1 | create table user6( |
当运行完成之后会发现,第一天的数据能够正常的插入成功,均匀的分散到3个分片上,但是第二天的数据就无法成功分散了,原因就在于我们的数据分片不够,所以这种方式几乎没有人使用。
日期范围hash分片
思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成了hash方法。先根据时间hash使得短期内数据分布的更均匀,有点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题,要求日期格式尽量精确,不然达不到局部均匀的目的。
1 | <table name="user7" dataNode="dn1,dn2,dn3" rule="rangeDateHash"></table> |
1 | <tableRule name="rangeDateHash"> |
1 | create table user7( |
通过结果也可以看出,每三天一个分片,那么我们只有三个数据节点,所以到10号的数据的时候,没有办法进行数据的插入了,原因就在于没有足够多的数据节点。
冷热数据分片
根据日期查询冷热数据分布,最近n个月的到实时交易库查询,其他的到其他库中
1 | <table name="user8" dataNode="dn1,dn2,dn3" rule="sharding-by-hotdate" /> |
1 | <tableRule name="sharding-by-hotdate"> |
1 | CREATE TABLE user8(create_time timestamp NULL ON UPDATE CURRENT_TIMESTAMP ,`db_nm` varchar(20) NULL); |
自然月分片
1 | <table name="user9" dataNode="dn1,dn2,dn3" rule="sharding-by-month" /> |
1 | <tableRule name="sharding-by-month"> |
1 | CREATE TABLE user9(id int,name varchar(10),create_time varchar(20)); |
一致性hash分片
实现方式:一致性hash分片,利用一个分片节点对应一个或者多个虚拟hash桶的思想,,尽可能减少分片扩展时的数据迁移。
优点:有效解决了分布式数据库的扩容问题。
缺点:在横向扩展的时候,需要迁移部分数据;由于虚拟桶倍数与分片节点数都必须是正整数,而且要服从”虚拟桶倍数×分片节点数=设计极限”,因此在横向扩容的过程中,增加分片节点并不是一台一台地加上去的,而是以一种因式分解的方式增加,因此有浪费物理计算力的可能性。
1 | <table name="user10" dataNode="dn1,dn2,dn3" primaryKey="id" rule="sharding-by-murmur" /> |
1 | <tableRule name="sharding-by-murmur"> |
3、重启mycat服务
4、创建mycat表
1 | create table user10(id bigint not null primary key,name varchar(20)); |
分片join
Join绝对是关系型数据库中最常用的一个特性,然而在分布式环境中,跨分配的join却是最复杂的,最难解决的一个问题。
性能建议:
1、尽量避免使用left join或right join,而用inner join
2、在使用left join或right join时,on会优先执行,where条件在最后执行,所以再使用过程中,条件尽可能的在on语句中判断,减少where的执行
3、少使用子查询,而用join
mycat目前版本支持跨分配的join,主要有四种实现方式
1、全局表
2、ER分片
3、catletT(人工智能)
4、ShareJoin
全局表和ER分片在之前的操作中已经讲过了,此处不再赘述,下面详细讲解下另外两种方式。
Share join
ShareJoin是一个简单的跨分片join,基于HBT的方式实现。目前支持2个表的join,原理是解析SQL语句,拆分成单表的SQL语句执行,然后把各个节点的数据汇集。
配置方式如下:
A,B的dataNode相同
1 | <table name="A" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> |
A,B的dataNode不同
1 | <table name="A" dataNode="dn1,dn2 " rule="auto-sharding-long" /> |
修改schema.xml
1 | <table name="company" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long" /> |
修改rule.xml
1 | <tableRule name="mod-long"> |
修改partition-hash-int.txt文件
1 | 10000=0 |
1 | create table company(id int primary key,name varchar(10)) engine=innodb; |
1 | -- 可以看到有时可以查出对应的结果,有时则查询不到 |
全局序列号
在实现分库分表的情况下,数据库自增主键已经无法保证自增主键的全局唯一,为此,mycat提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
本地文件方式
使用此方式的时候,mycat讲sequence配置到文件中,当使用到sequence中的配置,mycat会更新sequence_conf.properties文件中sequence当前的值。
配置方式:
在 sequence_conf.properties 文件中做如下配置:
1 | = |
其中 HISIDS 表示使用过的历史分段(一般无特殊需要可不配置), MINID 表示最小 ID 值, MAXID 表示最大
ID 值, CURID 表示当前 ID 值。
server.xml 中配置:
1 | <system><property name="sequnceHandlerType">0</property></system> |
注: sequnceHandlerType 需要配置为 0,表示使用本地文件方式。
案例使用:
1 | create table tab1(id int primary key,name varchar(10)); |
缺点:当mycat重新发布后,配置文件中的sequence会恢复到初始值
优点:本地加载,读取速度较快
数据库方式
在数据库中建立一张表,存放sequence名称(name),sequence当前值(current_value),步长(increment int类型,每次读取多少个sequence,假设为K)等信息;
获取数据步骤:
1、当初次使用该sequence时,根据传入的sequence名称,从数据库这张表中读取current_value和increment到mycat中,并将数据库中的current_value设置为原current_value值+increment值。
2、mycat将读取到current_value+increment作为本次要使用的sequence值,下次使用时,自动加1,当使用increment次后,执行步骤1中的操作
3、mycat负责维护这张表,用到哪些sequence,只需要在这张表中插入一条记录即可,若某次读取的sequence没有用完,系统就停掉了,则这次读取的sequence剩余值不会再使用
配置方式:
1、修改server.xml文件
1 | <system><property name="sequnceHandlerType">1</property></system> |
2、修改schema.xml文件
1 | <table name="test" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long"/> |
3、修改mycat配置文件sequence_db_conf.properties,添加属性值
1 | #sequence stored in datanode |
4、在dn2上添加mycat_sequence表
1 | DROP TABLE IF EXISTS mycat_sequence; |
5、在dn2上的mycat_sequence表中插入初始记录
1 | INSERT INTO mycat_sequence(name,current_value,increment) VALUES ('mycat', -99, 100); |
6、在dn2上创建函数
1 | --创建函数 |
数据测试:
1 | create table test(id int,name varchar(10)); |
1 | SELECT * FROM mycat_sequence; |
1 | insert into test(id,name) values(next value for MYCATSEQ_MYCAT,(select database())); |
1 | SELECT * FROM test order by id asc; |
1 | SELECT * FROM mycat_sequence; |
1 | SELECT * FROM test order by id asc; |
在使用的时候会发现报错的情况,这个错误的原因不是因为我们的配置,是因为我们的版本问题,简单替换下版本即可。
1 | mysql> insert into test(id,name) values(next value for MYCATSEQ_MYCAT,(select database())); |
本地时间戳方式
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)。
换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
使用方式:
1、配置server.xml文件
1 | <property name="sequnceHandlerType">2</property> |
2、修改sequence_time_conf.properties
1 | WORKID=06 #任意整数 |
3、修改schema.xml文件
1 | <table name="test2" dataNode="dn1,dn2,dn3" primaryKey="id" autoIncrement="true" rule="mod-long" /> |
4、启动mycat,并且创建表进行测试
1 | create table test2(id bigint auto_increment primary key,xm varchar(32)); |
此方式的优点是配置简单,但是缺点也很明显就是18位的id太长,需要耗费多余的存储空间。
自定义全局序列
用户还可以在程序中自定义全局序列,通过java代码来实现,这种方式一般比较麻烦,因此在能使用mycat提供的方式满足需求的前提下一般不需要自己通过java代码来实现。
最后更新: 2021年03月12日 15:57
